오토스케일링은 클라우드 컴퓨팅에서 자동으로 서버 또는 컴퓨팅 리소스를 늘리거나 줄이는 기술입니다. 이 기술은 트래픽이나 작업 부하가 증가 또는 감소할 때 자원을 동적으로 조정하여 성능을 최적화하고 비용을 절감합니다. 주요 클라우드 서비스 제공업체들은 자체적인 오토스케일링 기능을 제공하며, 다양한 설정을 통해 사용자가 조절할 수 있습니다. 이는 웹 애플리케이션, 마이크로서비스 아키텍처, 데이터 처리 작업 등 다양한 환경에서 유용하게 활용됩니다.
Amazon Elastic Kubernetes Service (EKS)에서 Autoscaling을 하는 이유는 다음과 같습니다.
- 자원 최적화: Kubernetes 클러스터는 어플리케이션의 요구에 따라 자동으로 스케일링됩니다. 요청이 증가하면 자동으로 클러스터에 더 많은 인스턴스를 배포하여 성능을 유지할 수 있습니다. 이는 자원을 효율적으로 사용하고 비용을 절감하는 데 도움이 됩니다.
- 부하 관리: Autoscaling은 애플리케이션의 부하를 관리하는 데 도움이 됩니다. 트래픽이 증가하면 클러스터는 자동으로 확장하여 추가 요청을 처리할 수 있습니다. 반대로 트래픽이 감소하면 자원을 축소하여 비용을 절감할 수 있습니다.
- 고가용성 및 신뢰성: Autoscaling은 고가용성 및 신뢰성을 향상시킵니다. 예를 들어, 서비스에 장애가 발생하면 Autoscaling을 사용하여 영향을 줄일 수 있습니다. 또한, 클러스터에 장애가 있는 경우 자동으로 새로운 인스턴스를 생성하여 시스템의 가용성을 유지할 수 있습니다.
- 수동 개입 감소: Autoscaling을 사용하면 운영자가 수동으로 인스턴스를 추가하거나 제거할 필요가 없습니다. 이는 관리 작업을 감소시키고 시스템을 자동화하는 데 도움이 됩니다.
HPA(Horizontal Pod Autoscaler)
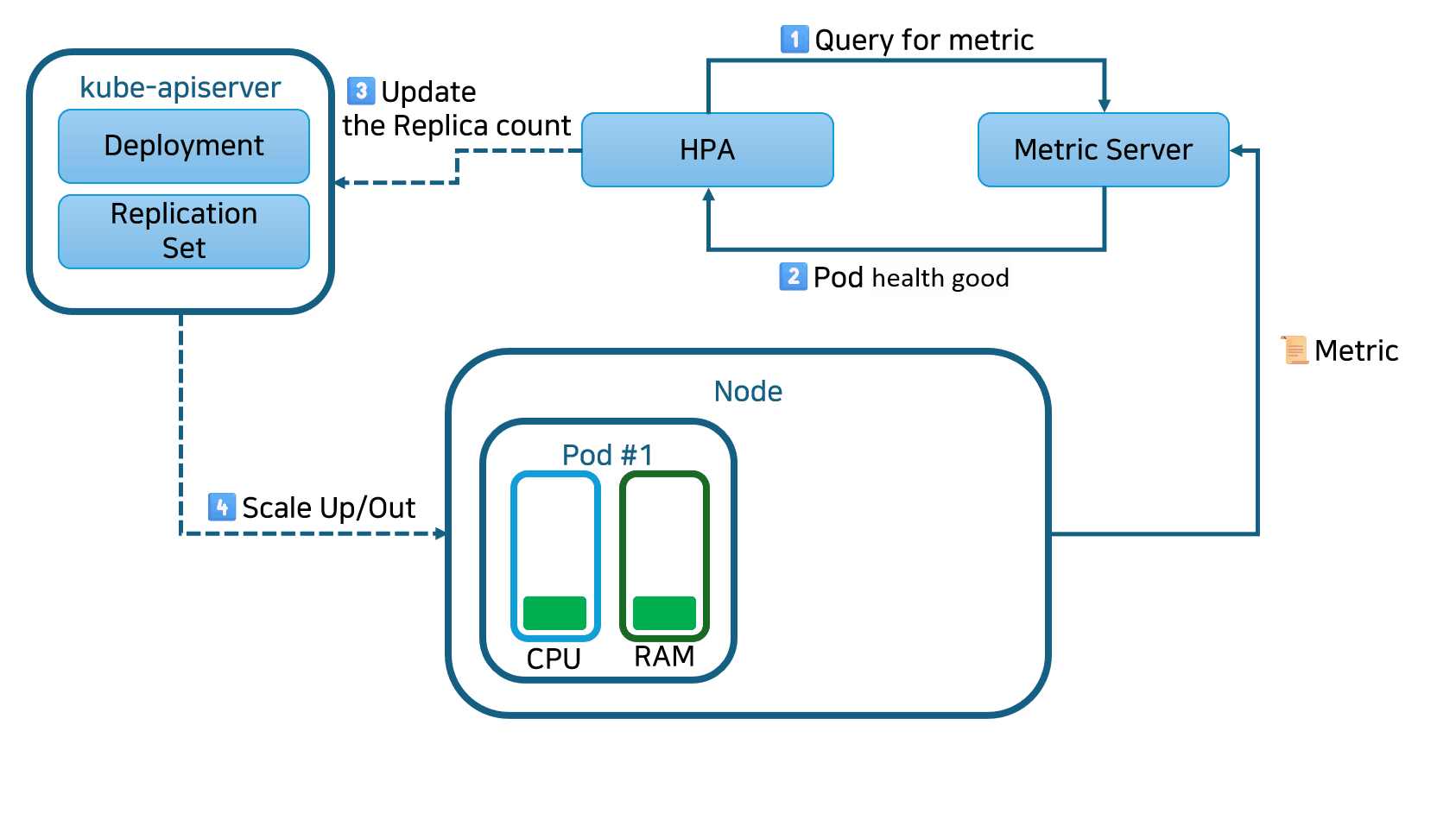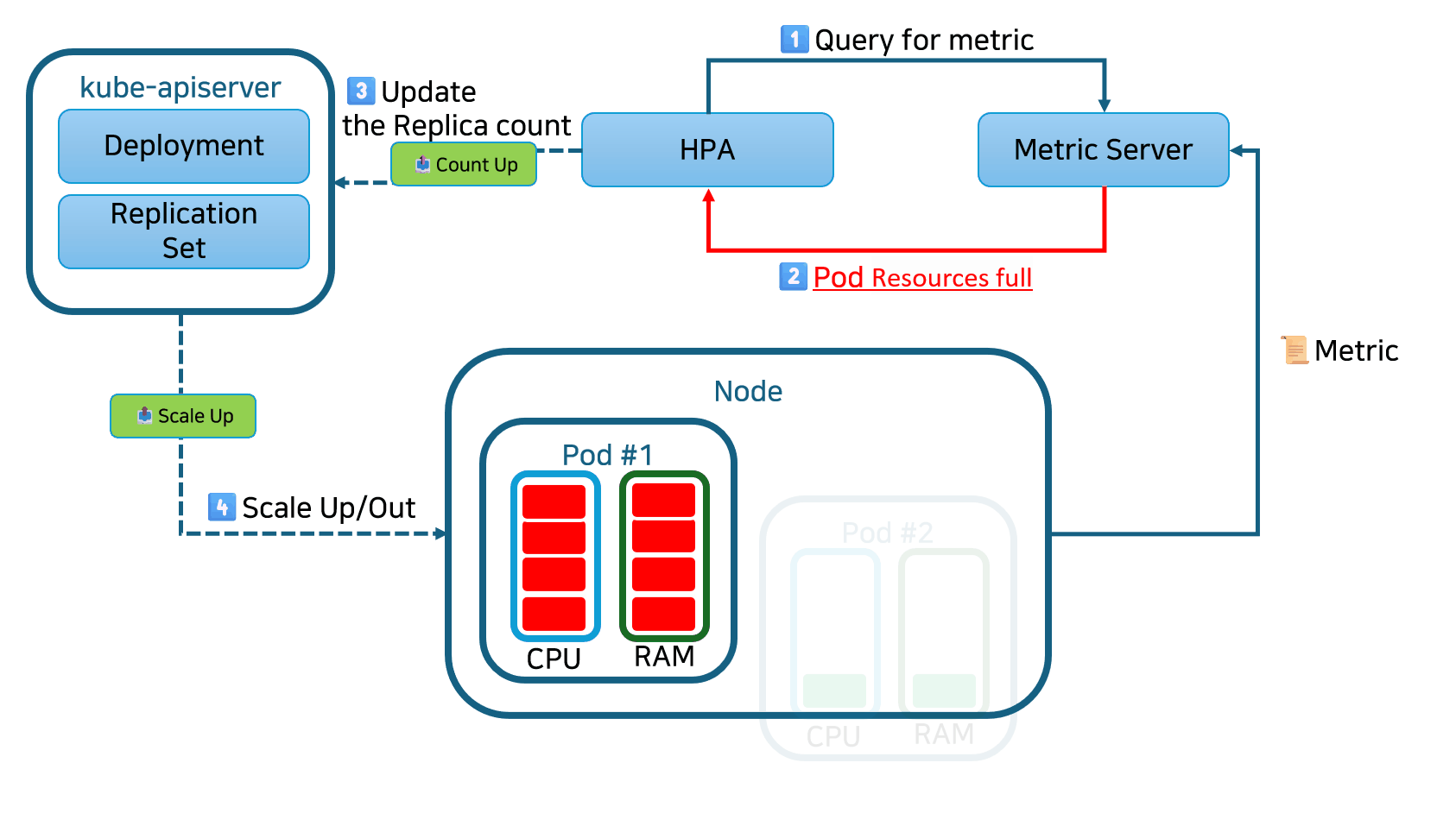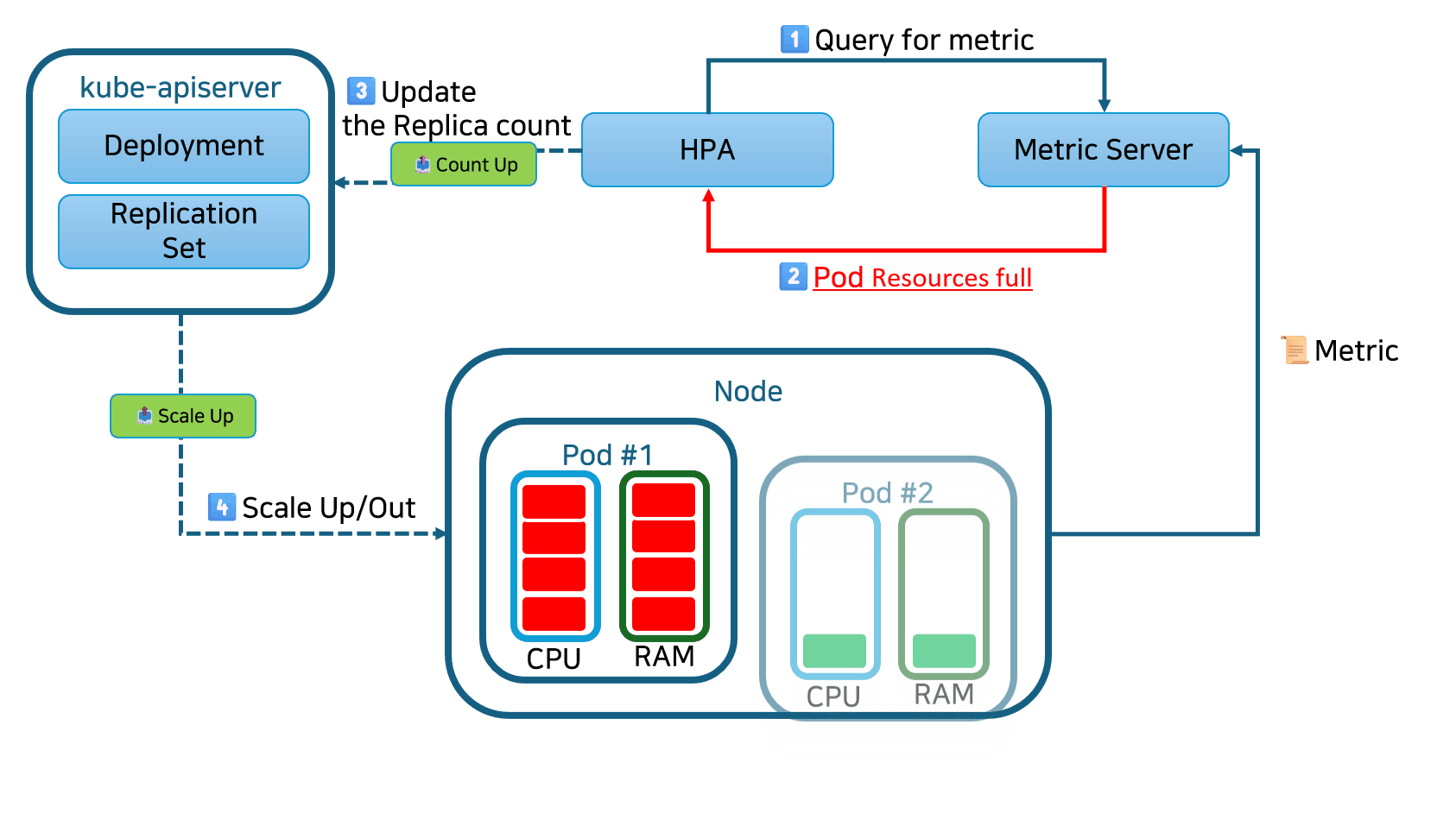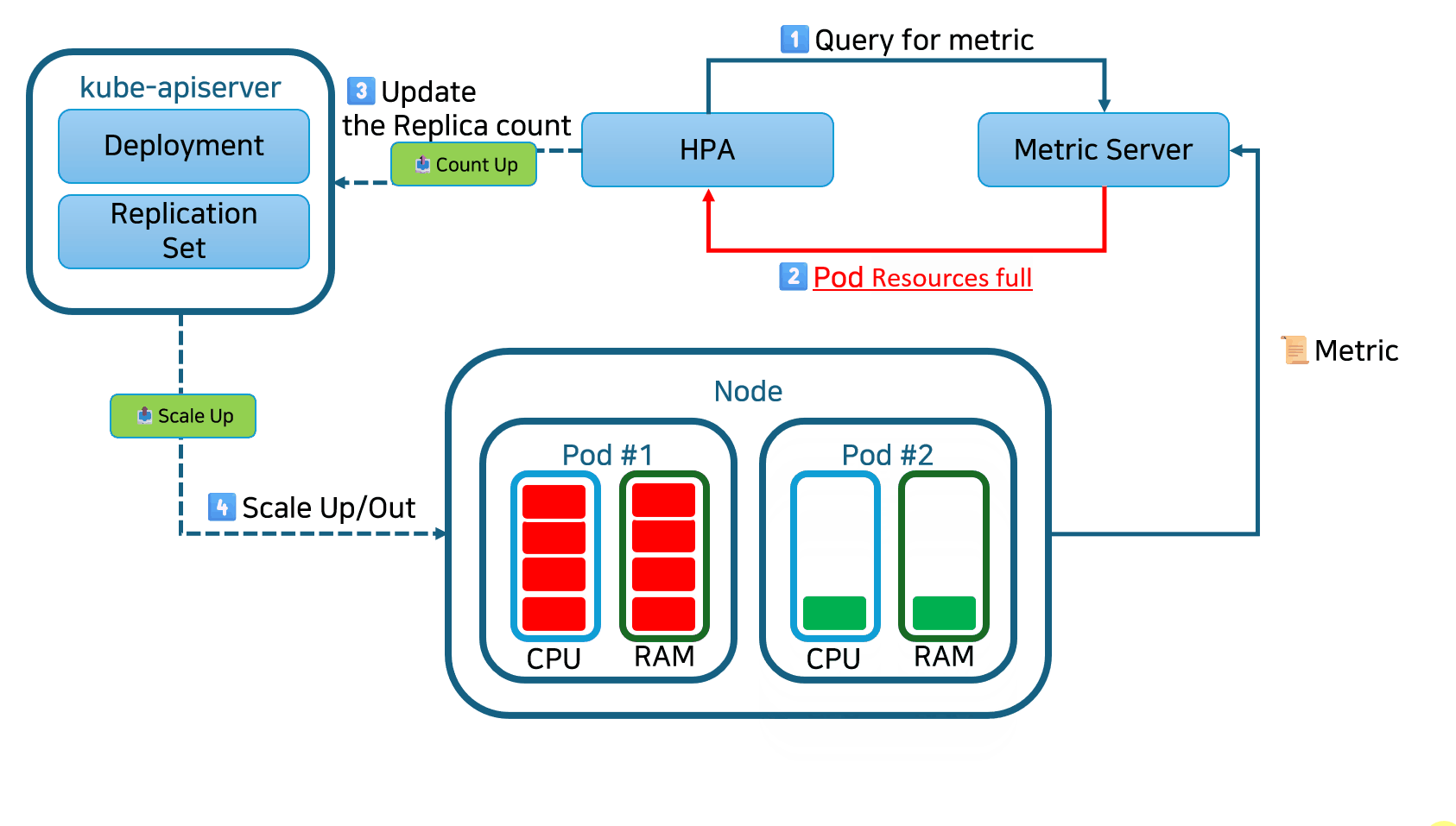
HPA(Horizontal Pod Autoscaler)는 CPU 사용률에 따라 레플리케이션 컨트롤러, 디플로이먼트, 레플리카셋 또는 스테이트풀셋 내의 파드 수를 증가 또는 감소시키는 형태의 자동 스케일링입니다. 스케일링은 단일 컨테이너에 할당된 리소스가 아닌 인스턴스 수를 변경하므로 수평적인 스케일링으로 간주됩니다.
HPA는 사용자 정의 또는 외부에서 제공된 메트릭을 기반으로 스케일링 결정을 내릴 수 있으며, 초기 구성 이후에는 자동으로 작동합니다. 필요한 것은 최소 및 최대 레플리카 수를 정의하는 것뿐입니다.
한번 설정된 후에는, Horizontal Pod Autoscaler 컨트롤러가 메트릭을 확인하고 레플리카를 적절하게 확장 또는 축소합니다. 기본적으로 HPA는 15초마다 메트릭을 확인합니다.
메트릭을 확인하기 위해서 HPA는 Metrics Server라는 다른 Kubernetes 리소스에 의존합니다. Metrics Server는 노드 및 파드에 대한 CPU 및 메모리 사용량과 같은 표준 리소스 사용 측정 데이터를 제공합니다. 또한 트래픽 양을 나타내는 로드 밸런서의 활성 세션 수와 같은 사용자 정의 메트릭(외부 소스에서 수집 가능)에도 액세스할 수 있습니다.
단점
HPA 적용 및 실습
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
kubectl describe hpa
KEDA(Kubernetes based Event Driven Autoscaler)
기존의 HPA(Horizontal Pod Autoscaler)는 리소스(CPU, Memory) 메트릭을 기반으로 스케일 여부를 결정하게 됩니다. 반면에 KEDA는 특정 이벤트를 기반으로 스케일 여부를 결정할 수 있습니다. 예를 들어 airflow는 metadb를 통해 현재 실행 중이거나 대기 중인 task가 얼마나 존재하는지 알 수 있습니다. 이러한 이벤트를 활용하여 worker의 scale을 결정한다면 queue에 task가 많이 추가되는 시점에 더 빠르게 확장할 수 있습니다.
VPA(Verical Pod Autoscaler)
- VPA Recommender는 메트릭 서버에서 VPA 구성 및 리소스 사용률 메트릭을 읽습니다.
- VPA Recommender는 pod 리소스 권장 사항을 제공합니다.
- VPA Updater는 pod 리소스 권장 사항을 읽습니다.
- VPA Updater가 pod 종료를 시작합니다.
- Deployment는 pod가 종료되었음을 인식하고 복제본 구성과 일치하도록 pod를 다시 생성합니다.
- pod가 재생성 프로세스에 있을 때 VPA 승인 컨트롤러는 pod 리소스 권장 사항을 받습니다. Kubernetes는 실행 중인 Pod의 리소스 제한을 동적으로 변경하는 것을 지원하지 않으므로 VPA는 기존 Pod를 새로운 제한으로 업데이트할 수 없습니다. 오래된 제한을 사용하는 Pod를 종료합니다. Pod의 컨트롤러가 Kubernetes API 서비스에서 교체를 요청하면 VPA Admission Cotroller는 업데이트된 리소스 요청과 제한 값을 새 Pod의 사양에 삽입합니다.
- 마지막으로 VPA Admission Controller는 pod에 대한 권장 사항을 덮어씁니다.
단점
- VPA와 동일한 리소스 메트릭(예: CPU 및 메모리 사용량)을 기반으로 스케일링하는 수평적인 파드 오토 스케일러(HPA)와 함께 사용할수가 없습니다. 메트릭(CPU/메모리)이 정의된 임계값에 도달하면 VPA와 HPA 모두에서 동시에 스케일링 이벤트가 발생하며, 문제가 발생할 수 있습니다.
- VPA는 클러스터에 사용 가능한 리소스보다 더 많은 리소스를 권장할 수 있으며, 이로 인해 파드가 노드에 할당되지 않고(리소스가 부족하여) 실행되지 않을 수 있습니다. 이 제한을 극복하기 위해, 최대 사용 가능한 리소스에 대한 LimitRange를 설정하는 것이 좋습니다. 이렇게하면 파드가 LimitRange에서 정의한 리소스보다 많은 리소스를 요청하지 않도록 보장됩니다.

Note:
Recommend mode에서 VPA를 실행할 수도 있습니다. VPA Recommand는 워크로드의 Vertical Pod Autoscaler 리소스의 상태 필드를 제안된 값으로 업데이트하지만 Pod를 종료하거나 Pod API 요청을 변경하지는 않습니다.
VPA 적용 및 실습
# 코드 다운로드
git clone https://github.com/kubernetes/autoscaler.git
cd ~/autoscaler/vertical-pod-autoscaler/
openssl11 version #OpenSSL 1.1.1g FIPS 21 Apr 2020
# 스크립트파일내에 openssl11 수정
sed -i 's/openssl/openssl11/g' ~/autoscaler/vertical-pod-autoscaler/pkg/admission-controller/gencerts.sh
# Deploy the Vertical Pod Autoscaler to your cluster with the following command.
watch -d kubectl get pod -n kube-system
cat hack/vpa-up.sh
./hack/vpa-up.sh
kubectl apply -f examples/hamster.yaml && kubectl get vpa -w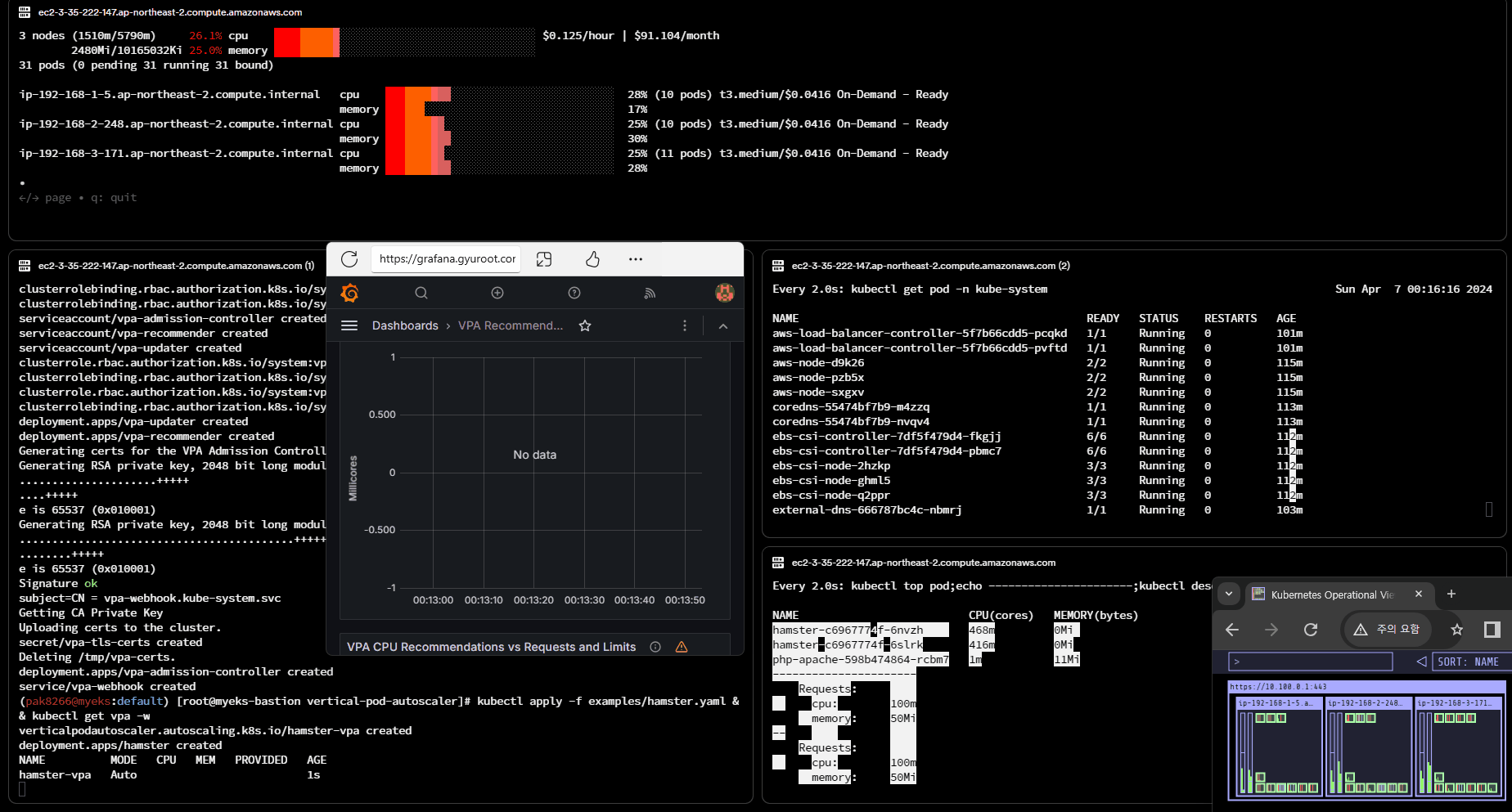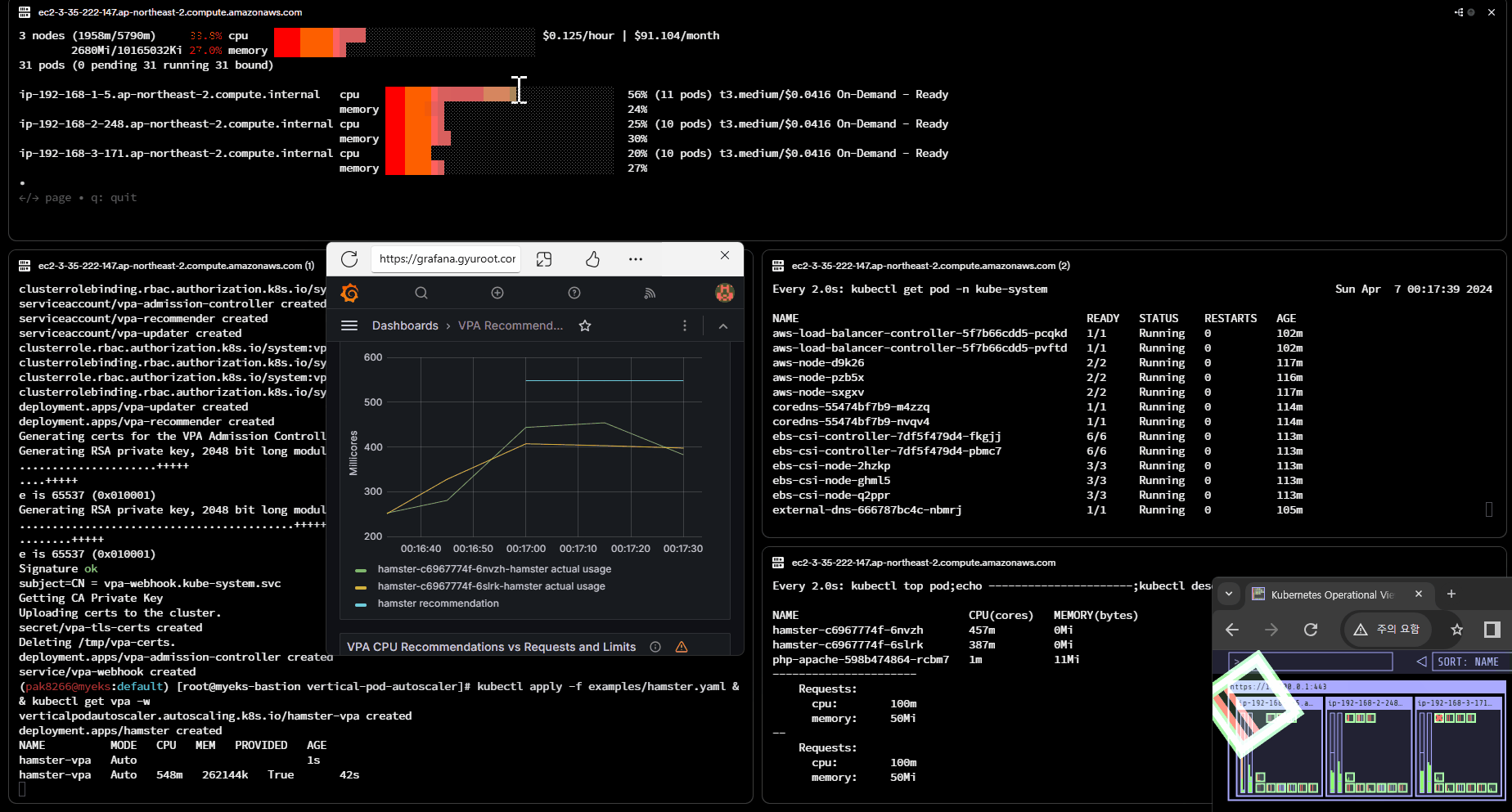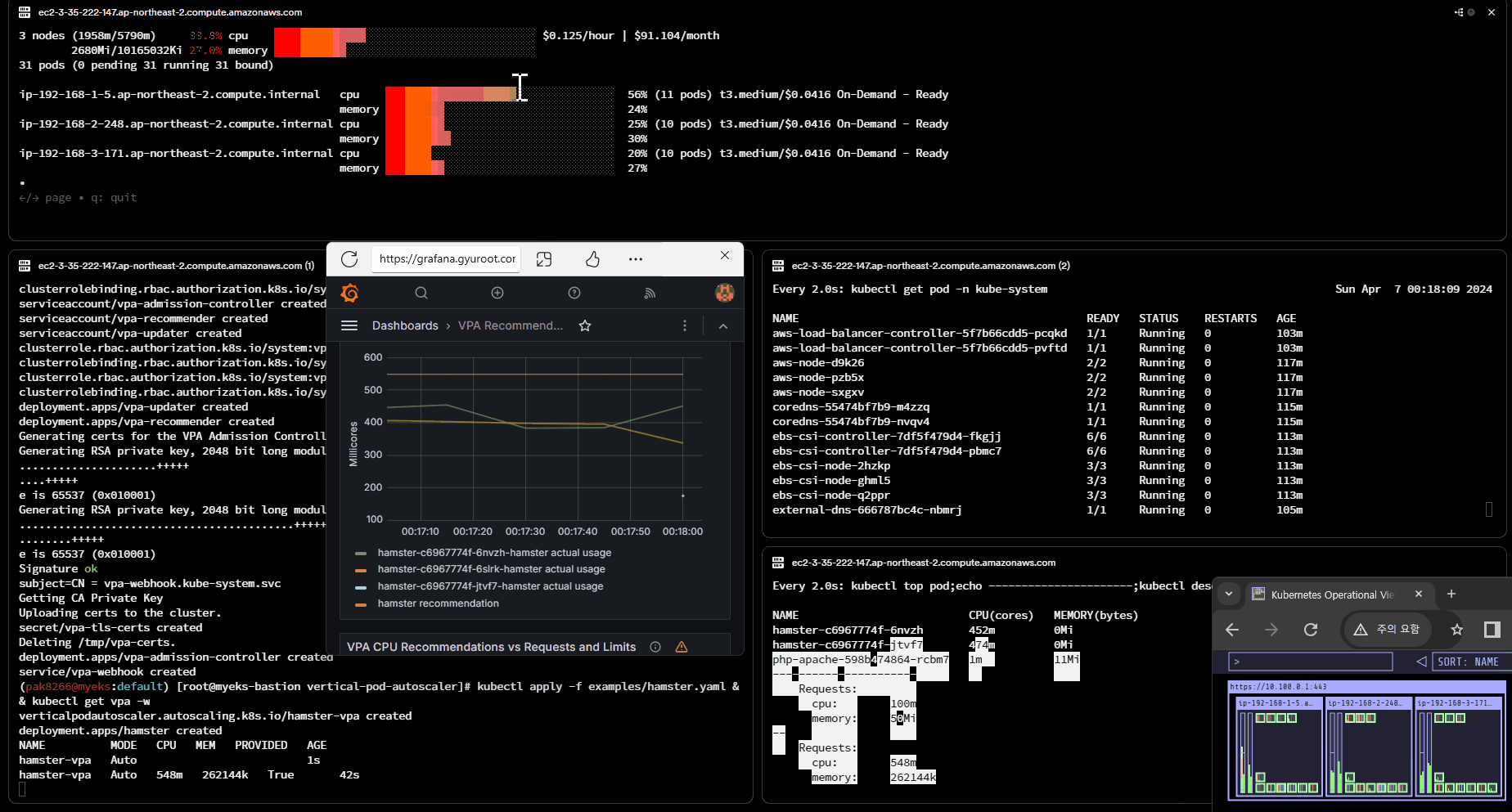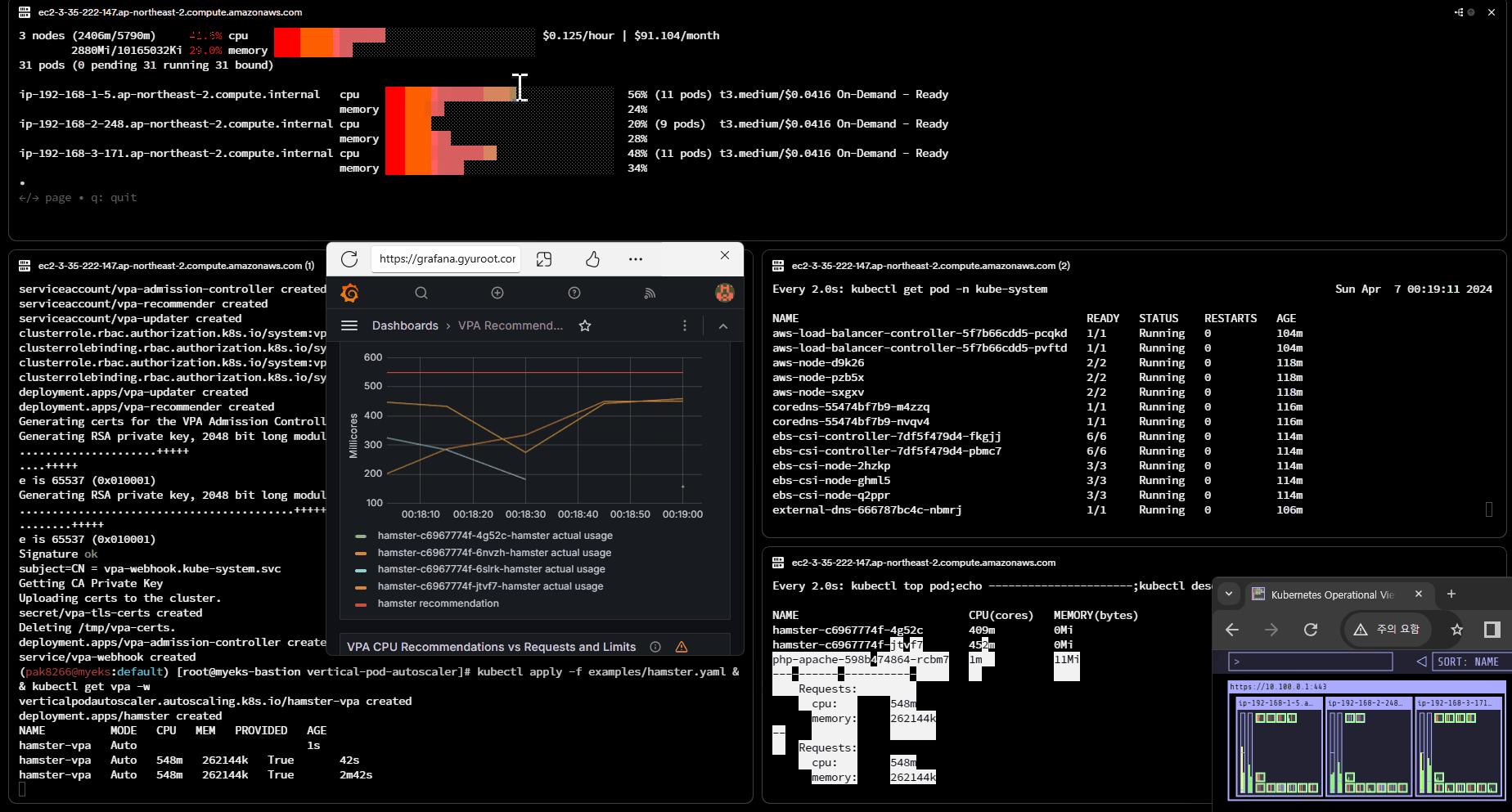
KRR(prometheus-based Kubernetes Resource Recommendations)
KRR (Kubernetes Resource Recommender)은 Kubernetes 클러스터의 리소스 사용을 최적화하기 위한 도구로, 자동으로 CPU 및 메모리 요청과 제한을 추천합니다.
- 설치 위치:
- KRR: 클러스터 외부에서 실행할 수 있으며, 클러스터 내부에 별도의 구성이 필요하지 않습니다.
- VPA: 클러스터 내에 설치되어야 하며, 각 워크로드에 대해 VPA 객체를 구성해야 합니다.
- 워크로드 구성:
- KRR: 각 워크로드에 대해 별도의 VPA 객체를 구성할 필요가 없습니다.
- VPA: 각 워크로드에 대해 VPA 객체를 구성해야 합니다.
- 즉각적인 결과:
- KRR: Prometheus가 가동되어 있으면 즉시 결과를 얻을 수 있습니다.
- VPA: 데이터 수집 및 권장 사항 제공에 시간이 소요됩니다.
- 보고서:
- KRR: 상세한 CLI 보고서와 웹 UI를 제공합니다.
- VPA: 보고서를 지원하지 않습니다.
- 확장성:
- KRR: 몇 줄의 Python 코드로 사용자 정의 전략을 추가할 수 있습니다.
- VPA: 확장성이 제한되어 있습니다.
- 사용자 정의 메트릭 및 리소스:
- KRR: 향후 버전에서 지원 예정입니다.
- VPA: 사용자 정의 메트릭 및 리소스를 지원하지 않습니다.
- 설명 가능성:
- KRR: 향후 버전에서 지원 예정으로, 추가 그래프를 제공할 예정입니다.
- VPA: 설명 가능성을 지원하지 않습니다.
- 오토 스케일링:
- KRR: 향후 버전에서 지원 예정입니다.
- VPA: 권장 사항이 자동으로 적용됩니다.
요약하면, KRR은 Kubernetes 클러스터의 리소스 사용을 최적화하기 위한 외부 도구로, 즉시 결과를 제공하고 설치 및 구성이 간편하며 사용자 정의 및 확장이 용이합니다. 반면 VPA는 클러스터 내부에 설치되어야 하며, 각 워크로드에 대한 별도의 구성이 필요하며, 즉각적인 결과를 제공하지 않습니다.
VPA vs KRR
| 기능 | Robusta KRR | Kubernetes VPA |
|---|---|---|
| 리소스 권장 사항 | CPU/Memory 요청 및 제한 | CPU/Memory 요청 및 제한 |
| 설치 위치 | 클러스터 내에 설치 필요 X | 클러스터 내에 설치 필요 O |
| 워크로드 구성 | 개별 워크로드에 VPA 객체 설정 불필요 | 개별 워크로드에 VPA 객체 설정 필요 |
| 즉각적인 결과 | 즉각적인 결과 (Prometheus 가동시) | 데이터 수집 및 권장 사항 제공에 시간 소요 |
| 보고서 | 상세한 CLI 보고서, Robusta.dev 웹 UI 제공 | 지원하지 않음 |
| 확장성 | 몇 줄의 Python 코드로 사용자 정의 전략 추가 가능 | 확장성 제한됨 |
| 사용자 정의 메트릭 | 향후 버전에서 지원 예정 | 지원하지 않음 |
| 사용자 정의 리소스 | 향후 버전에서 지원 예정 (예: GPU) | 지원하지 않음 |
| 설명 가능성 | 향후 버전에서 지원 예정 (Robusta는 추가 그래프 제공) | 지원하지 않음 |
| 오토 스케일링 | 향후 버전에서 지원 예정 | 권장 사항 자동 적용 |
CA(Cluster Autoscaling)
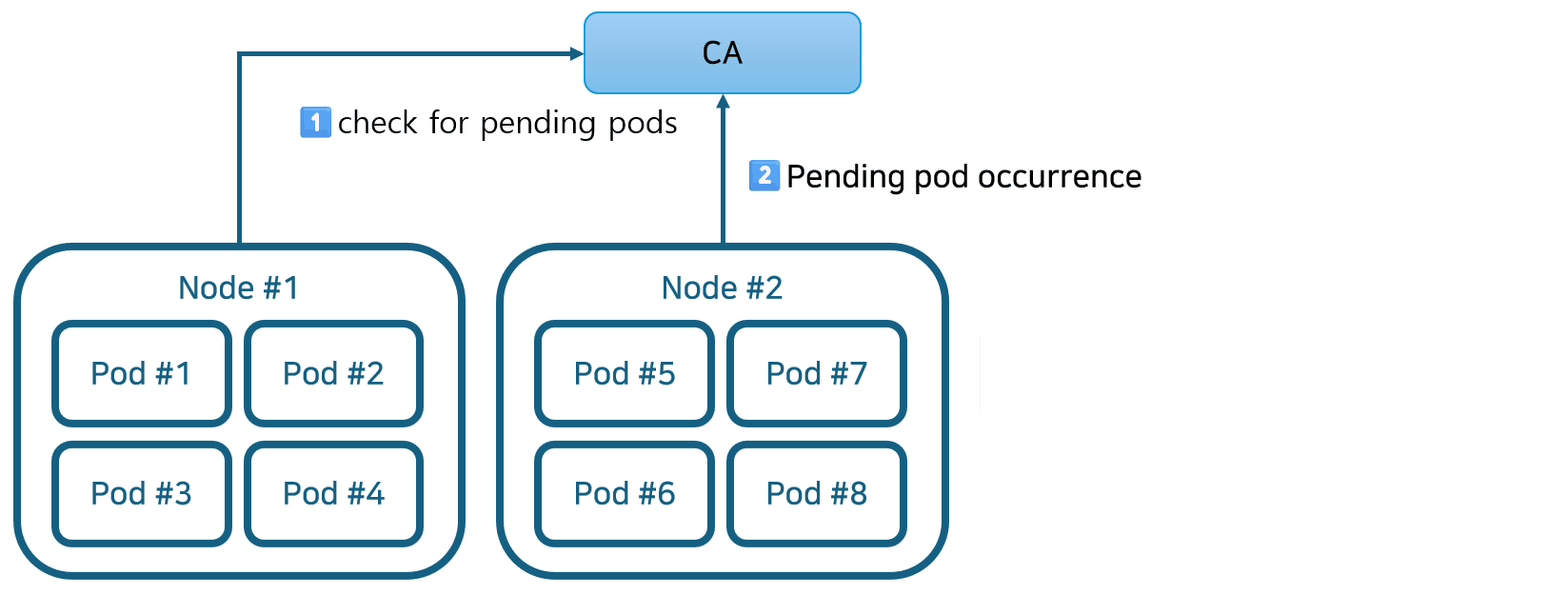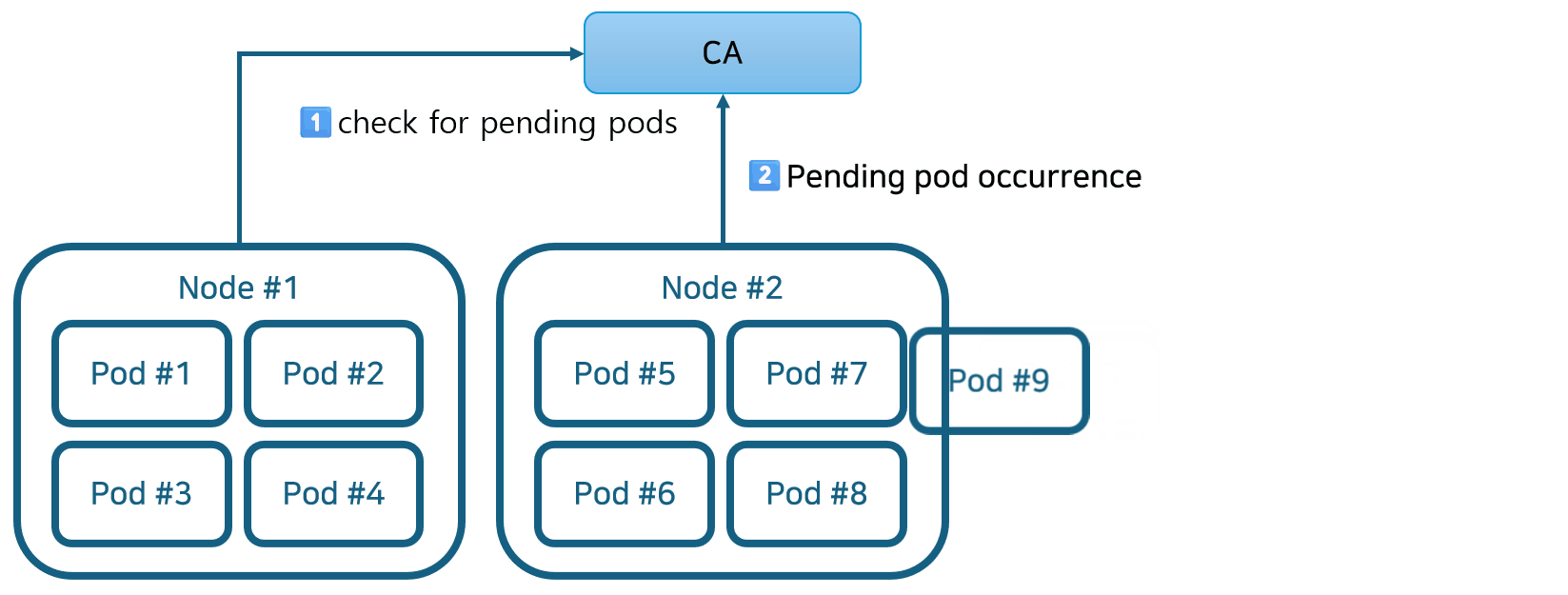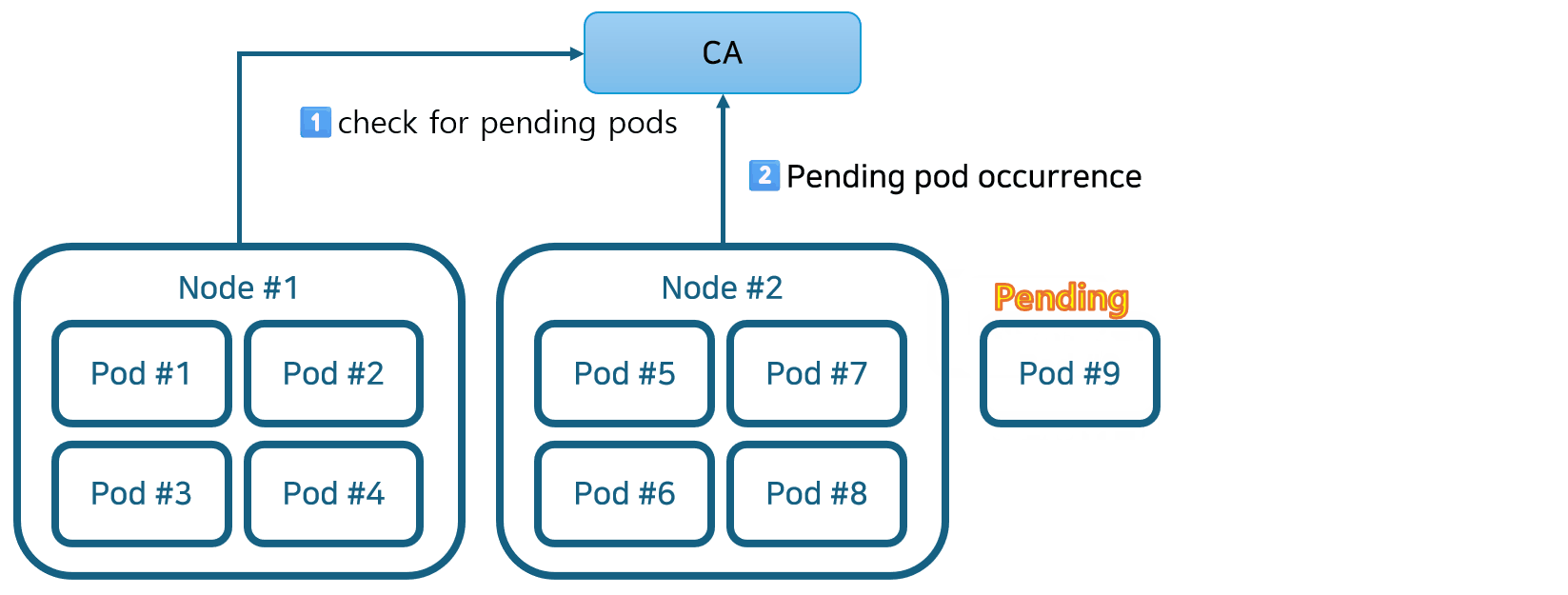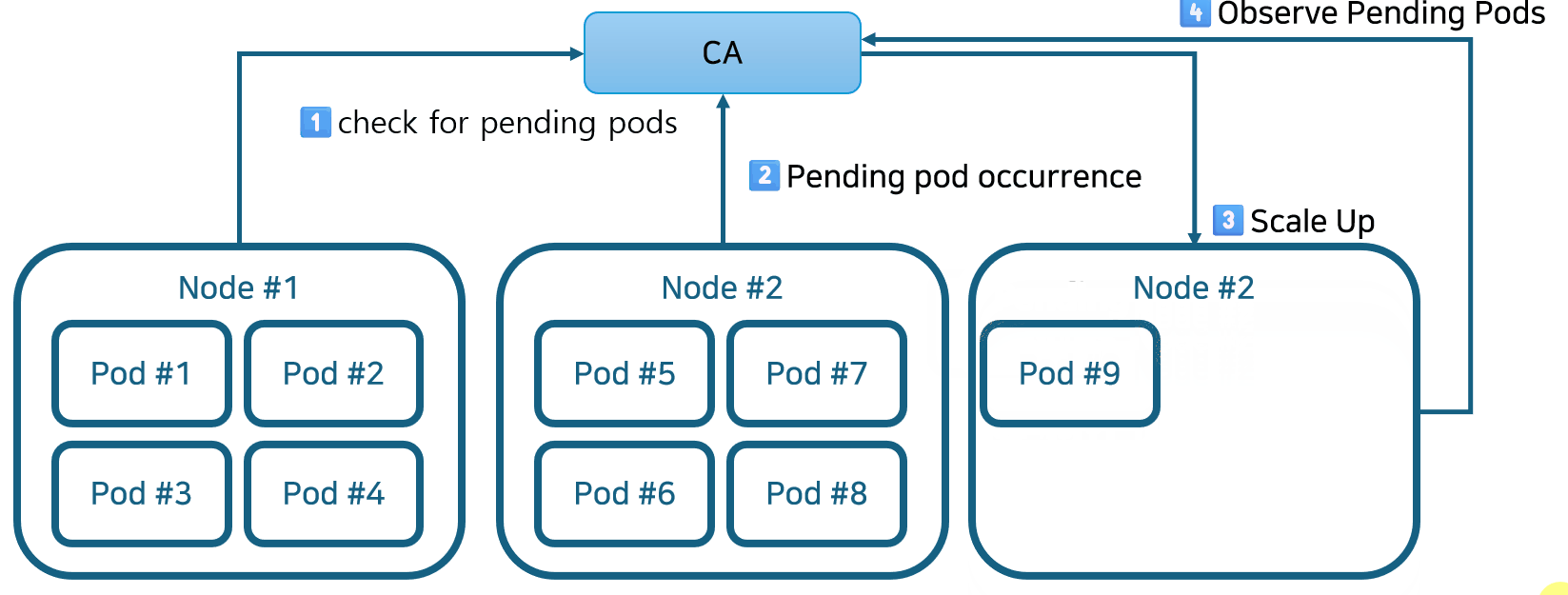
- Cluster Autoscaler가 활성화되면 보류 중인 Pod를 확인합니다. 기본 검색 간격은 10초이며 –scan-interval 플래그를 사용하여 구성할 수 있습니다.
- 보류 중인 포드가 있고 클러스터에 더 많은 리소스가 필요한 경우 CA는 관리자가 구성한 제약 조건 내에 있는 한 새 노드를 시작하여 클러스터를 확장합니다(이 예에서 자세히 설명). AWS, Azure, GCP와 같은 퍼블릭 클라우드 제공업체도 Kubernetes Cluster Autoscaler 기능을 지원합니다. 예를 들어, AWS EKS는 AWS Auto Scaling 그룹 기능을 사용하여 Kubernetes에 통합되어 클러스터 노드 역할을 하는 EC2 가상 머신을 자동으로 추가하고 제거합니다.
- Kubernetes는 새로 프로비저닝된 노드를 제어 플레인에 등록하여 Pod 할당을 위해 Kubernetes 스케줄러에서 사용할 수 있도록 합니다.
- 마지막으로 Kubernetes 스케줄러는 보류 중인 Pod를 새 노드에 할당합니다.
단점
- CA는 CPU 또는 메모리 사용량을 사용하여 확장 결정을 내리지 않습니다. CPU 및 메모리 리소스에 대한 Pod의 요청과 제한만 확인합니다. 이러한 제한은 사용자가 요청한 미사용 컴퓨팅 리소스를 CA에서 감지하지 못하여 클러스터가 낭비되고 활용 효율성이 낮다는 것을 의미합니다.
- 클러스터 확장 요청이 있을 때마다 폴링 방식인 CA는 30~60초 내에 클라우드 공급자에게 확장 요청을 보냅니다. 클라우드 공급자가 노드를 생성하는 데 걸리는 실제 시간은 몇 분 이상이 될 수 있습니다. 이러한 지연은 확장된 클러스터 용량을 기다리는 동안 애플리케이션 성능이 저하될 수 있으며, 자주 확장 여부를 확인하면 API제한에 도달할 수도 있습니다.
- ASG와 EKS의 관리 정보 동기화 문제로, 노드 관리 및 스케일링이 어렵습니다.
- ASG는 노드 생성/삭제에 직접 관여하지 않고, EKS에서 노드 삭제해도 인스턴스는 삭제되지 않습니다.
- 특정 노드 삭제하면서 동시에 노드 개수 줄이기 어려움.
- Cluster Autoscaler는 쿠버네티스 클러스터 오토 스케일링을 담당하며, Pending 상태의 파드 발생시 동작함. 스케일링은 기본적으로 최소 리소스 요청 기준으로 이뤄지며, 실제 리소스 사용량 고려하지 않음. CPU 및 메모리 리소스 할당 예시로 설명되었지만, 메모리의 경우도 동일한 원리가 적용됩니다.
CA 적용 및 실습
# 사전 확인
aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml | yh
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# aws autoscaling describe-auto-scaling-groups \
> --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
> --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-04c759c8-0fa3-9a6d-4cf4-c0feaf7db031 | 3 | 3 | 3 |
+------------------------------------------------+----+----+----+
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
-----------------------------------------------------------------
| DescribeAutoScalingGroups |
+------------------------------------------------+----+----+----+
| eks-ng1-04c759c8-0fa3-9a6d-4cf4-c0feaf7db031 | 3 | 6 | 3 |
+------------------------------------------------+----+----+----+ # MaxSize 6개로 수정
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
(k8s@myeks:default) [root@myeks-bastion vertical-pod-autoscaler]# kubectl apply -f cluster-autoscaler-autodiscover.yaml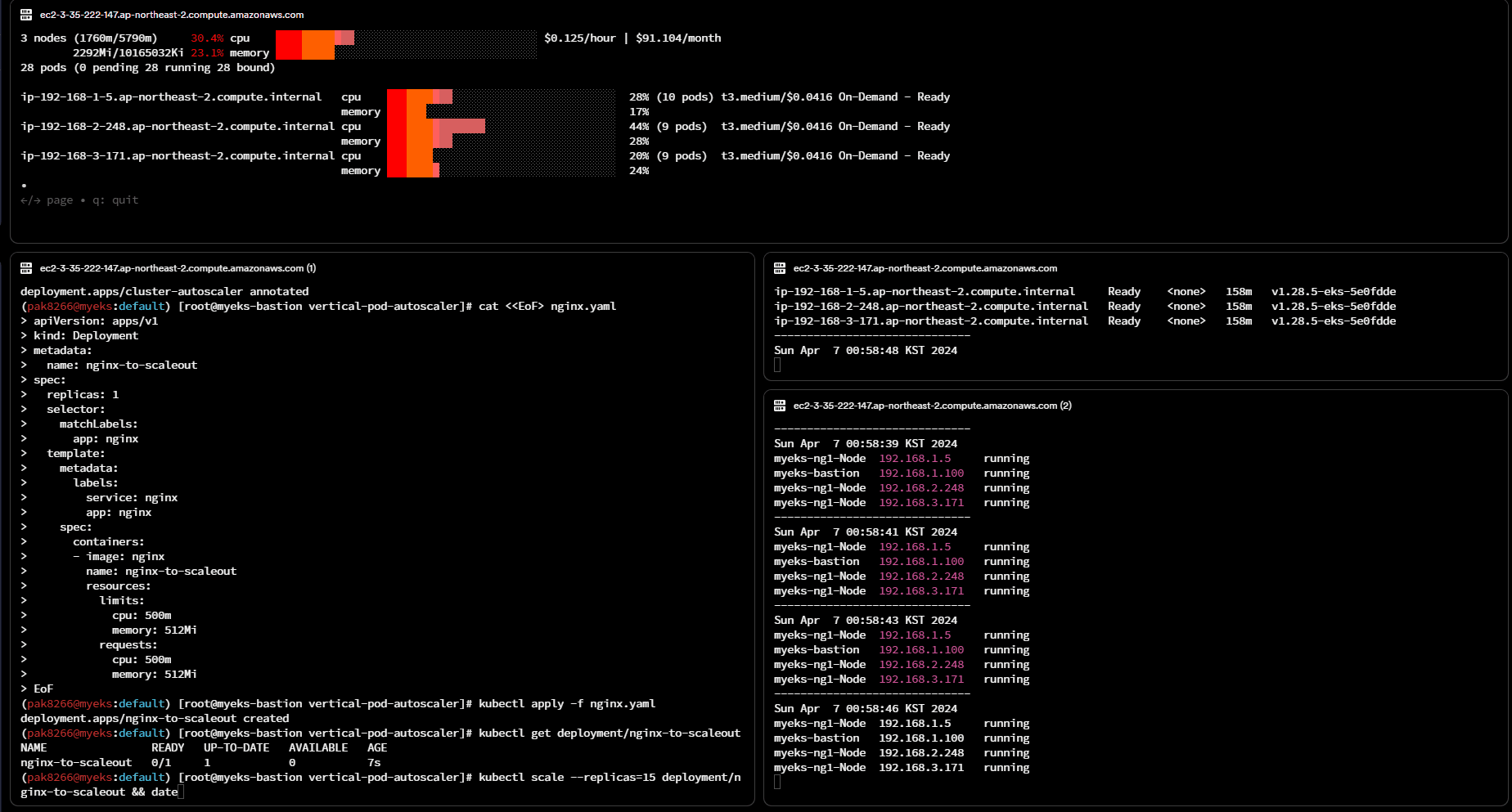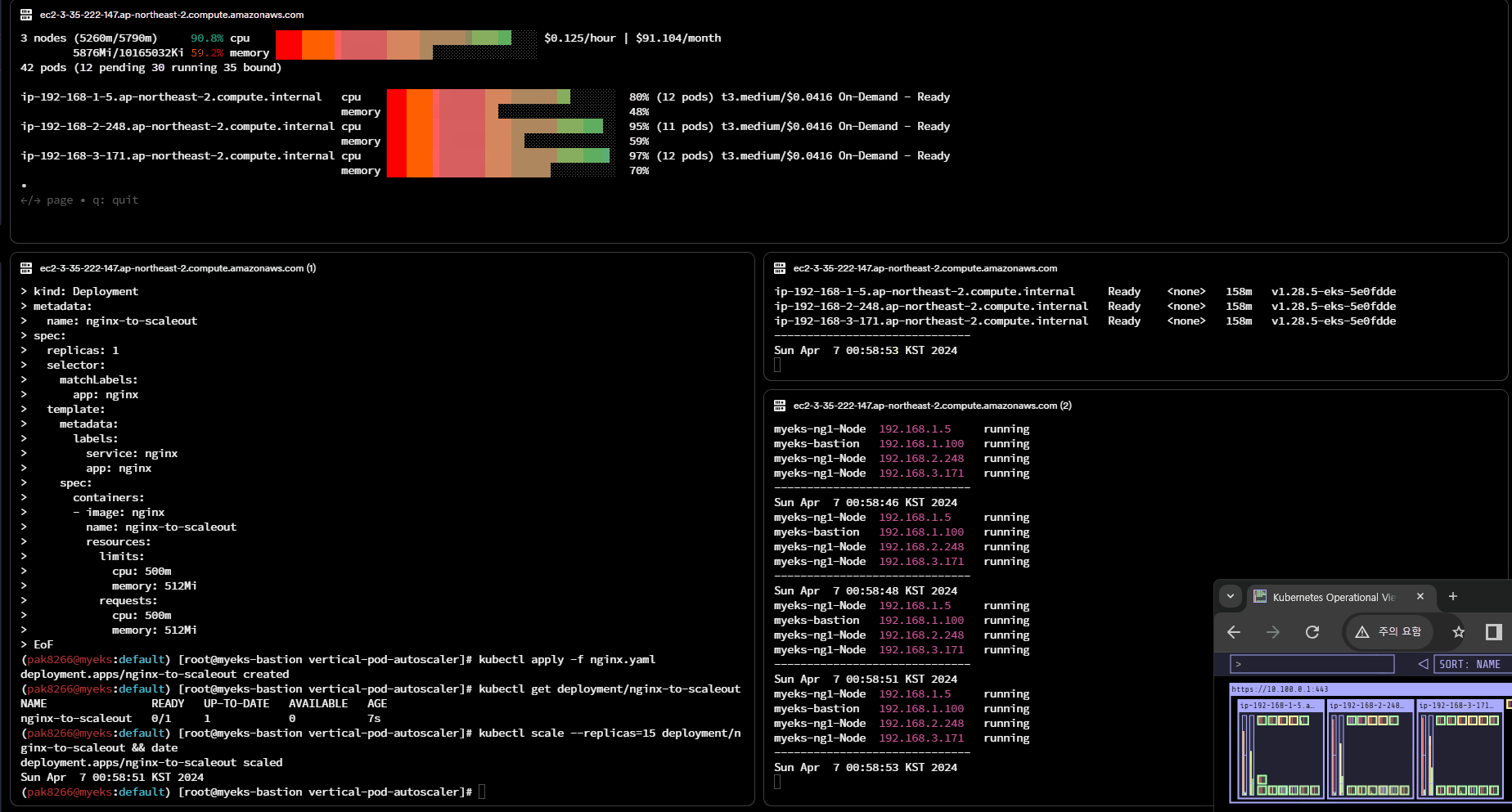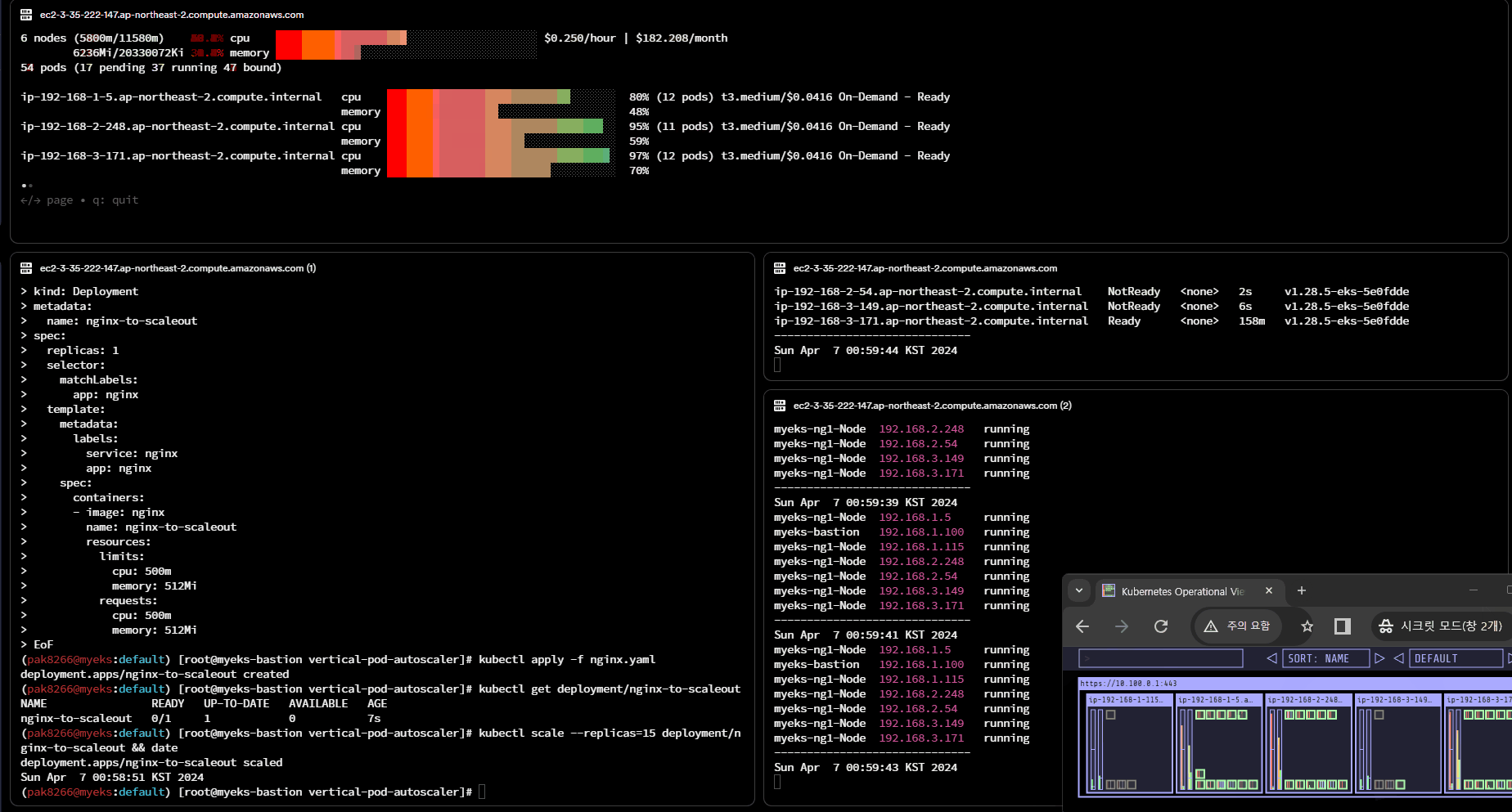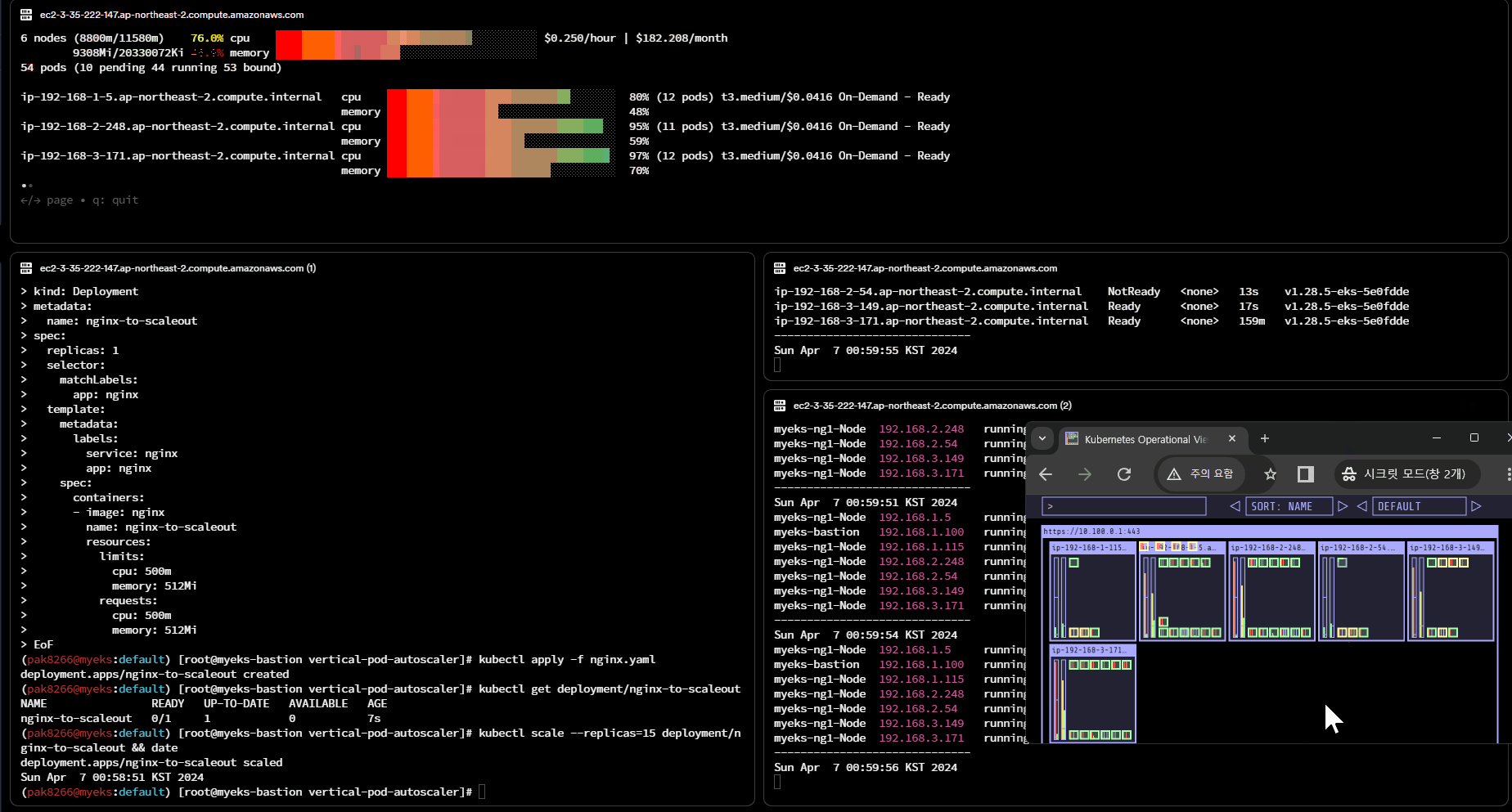
CPA(Cluster Proportional Autoscaler)
HPA 및 VPA는 리소스 사용량을 관리하고 현재 수요를 처리하기 위해 수평 및 수직 측면을 기반으로 애플리케이션을 조정하는 일반적인 방법입니다. CPA는 클러스터 규모에 따라 포드 복제본 수를 수평적으로 확장하는 것을 목표로 합니다. 일반적인 예로는 DNS 서비스가 있습니다. CPA는 현재 클러스터 규모(노드 수 또는 전체 CPU 용량)를 기반으로 DNS 인스턴스 수를 동적으로 조정할 수 있습니다.
트리거 조건
애플리케이션 자체의 리소스 사용량에 초점을 맞춘 HPA/VPA와 달리 CPA의 트리거 조정은 노드 자체 기능을 기반으로 합니다. 설정은 애플리케이션의 관점에서 시작하여 각 복제본이 처리할 수 있는 노드 인스턴스 또는 총 CPU 인스턴스 수를 탐색합니다. 관련 설정에는 coresPerReplica및 이 포함됩니다 nodesPerReplica. 현재 적합한 포드 수는 다음 공식을 사용하여 계산됩니다.
replicas = max(ceil(cores * 1/coresPerReplica), ceil(nodes * 1/nodesPerReplica))
CPA는 구성된 coresPerReplica및 nodesPerReplica현재 노드 규모를 기반으로 적절한 수를 계산합니다. 대상 Pod 복제본을 동적으로 조정합니다.
CPA 적용 및 실습
#
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
# CPA규칙을 설정하고 helm차트를 릴리즈 필요
helm upgrade --install cluster-proportional-autoscaler cluster-proportional-autoscaler/cluster-proportional-autoscaler
# nginx 디플로이먼트 배포
cat <<EOT > cpa-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
EOT
kubectl apply -f cpa-nginx.yaml
# CPA 규칙 설정
cat <<EOF > cpa-values.yaml
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
EOF
kubectl describe cm cluster-proportional-autoscaler
# 모니터링
watch -d kubectl get pod
# helm 업그레이드
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
# 노드 5개로 증가
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].AutoScalingGroupName" --output text)
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table
# 노드 4개로 축소
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" --output table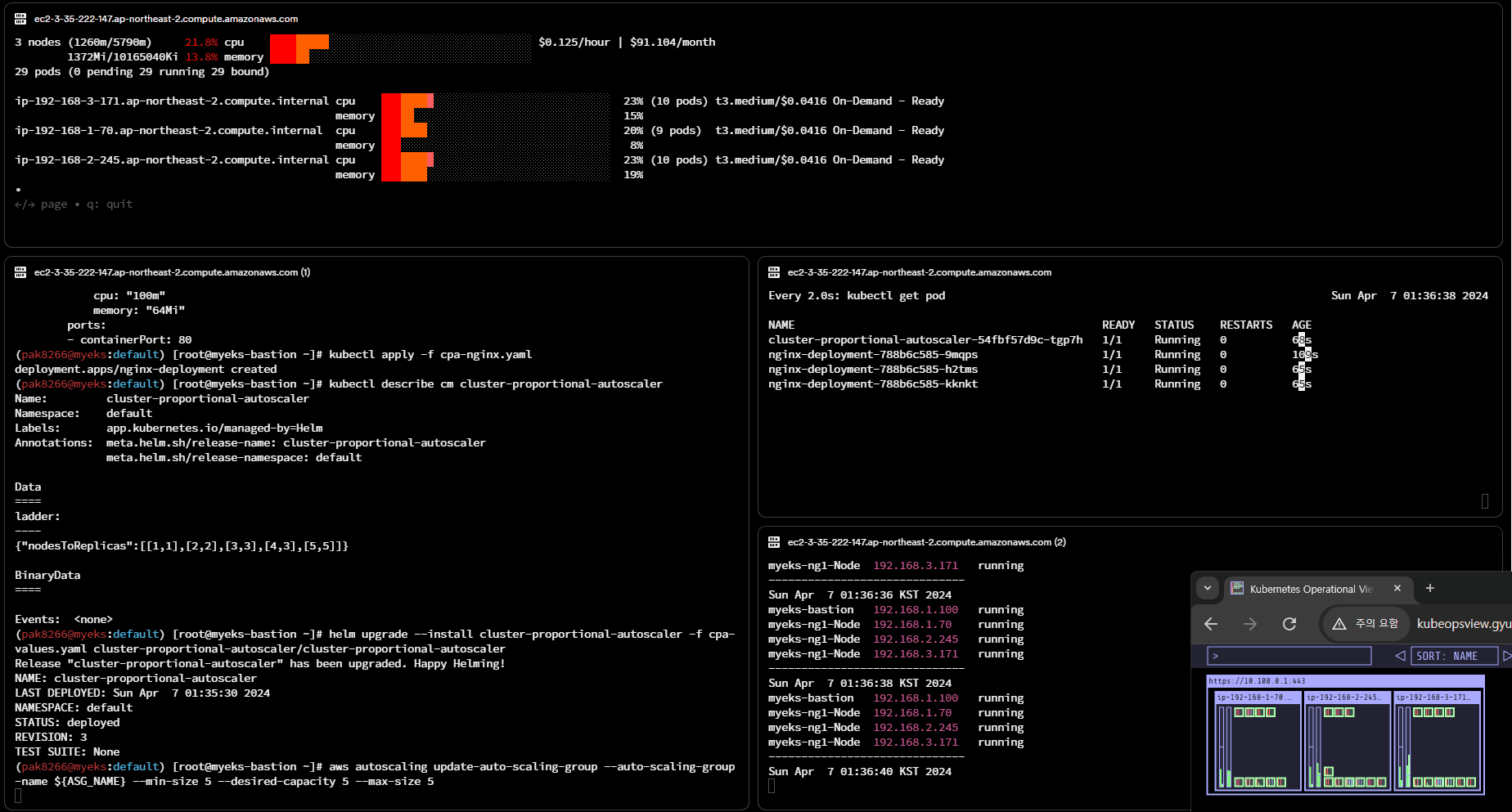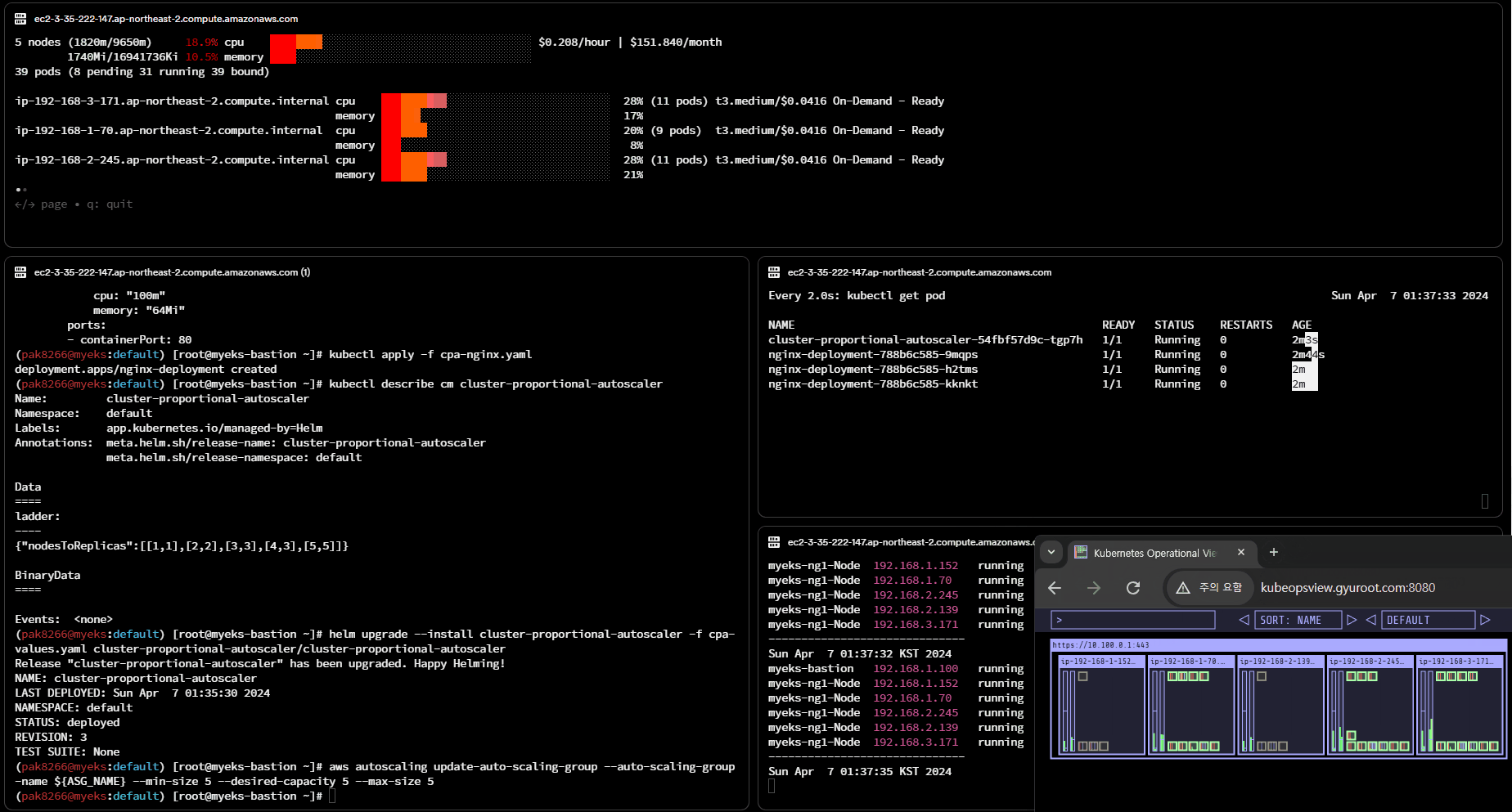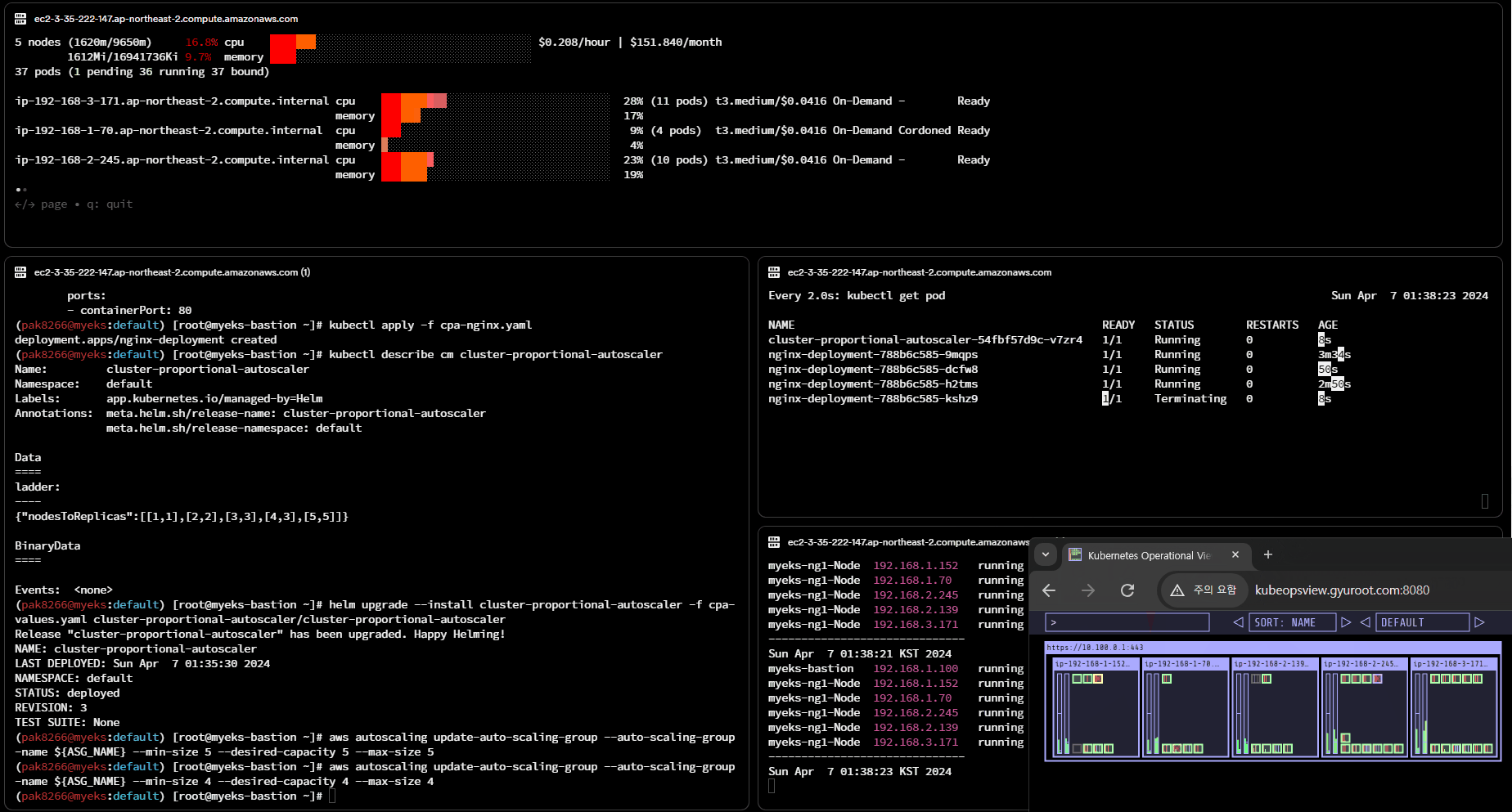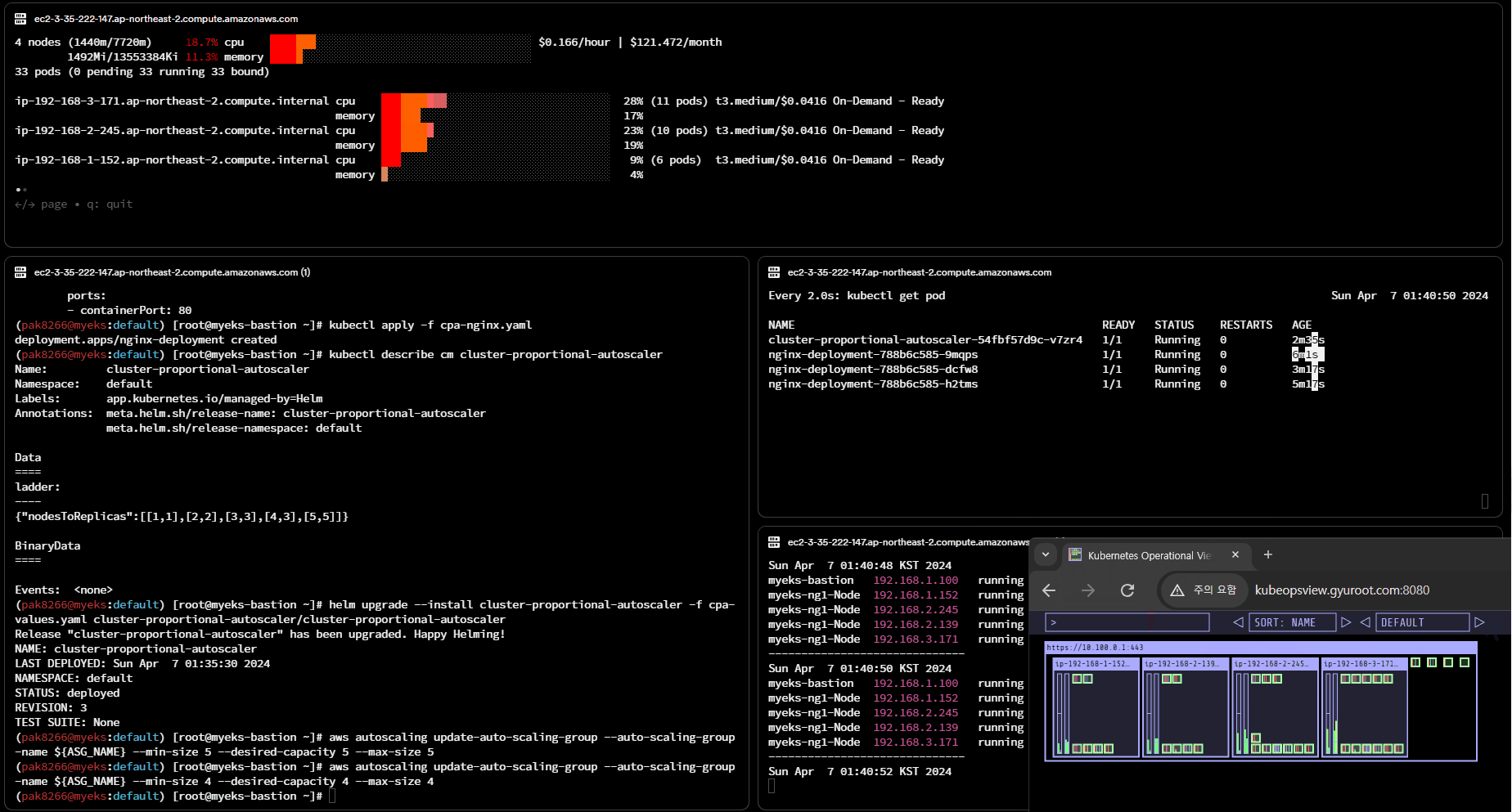
Karpenter(K8S Native AutoScaler)
쿠버네티스에서 클러스터의 오토 스케일링과 관련된 작업을 자동화하는 오픈 소스 프로젝트입니다. 이 서비스는 AWS, GCP, Azure 및 기타 인프라 플랫폼과 호환되며, 다양한 클라우드 환경에서 사용할 수 있습니다.
- 고성능 쿠버네티스 클러스터 오토 스케일러(Autoscaler)
- 기존 오토스케일러 보다 약 10배정도 빠름 (10분 -> 1분)
- 적절한 노드 사양을 결정하여 노드 생성
- kube-scheduler 대신 직접 pod를 스케줄링
- EKS 아닌 환경에서도 사용 가능
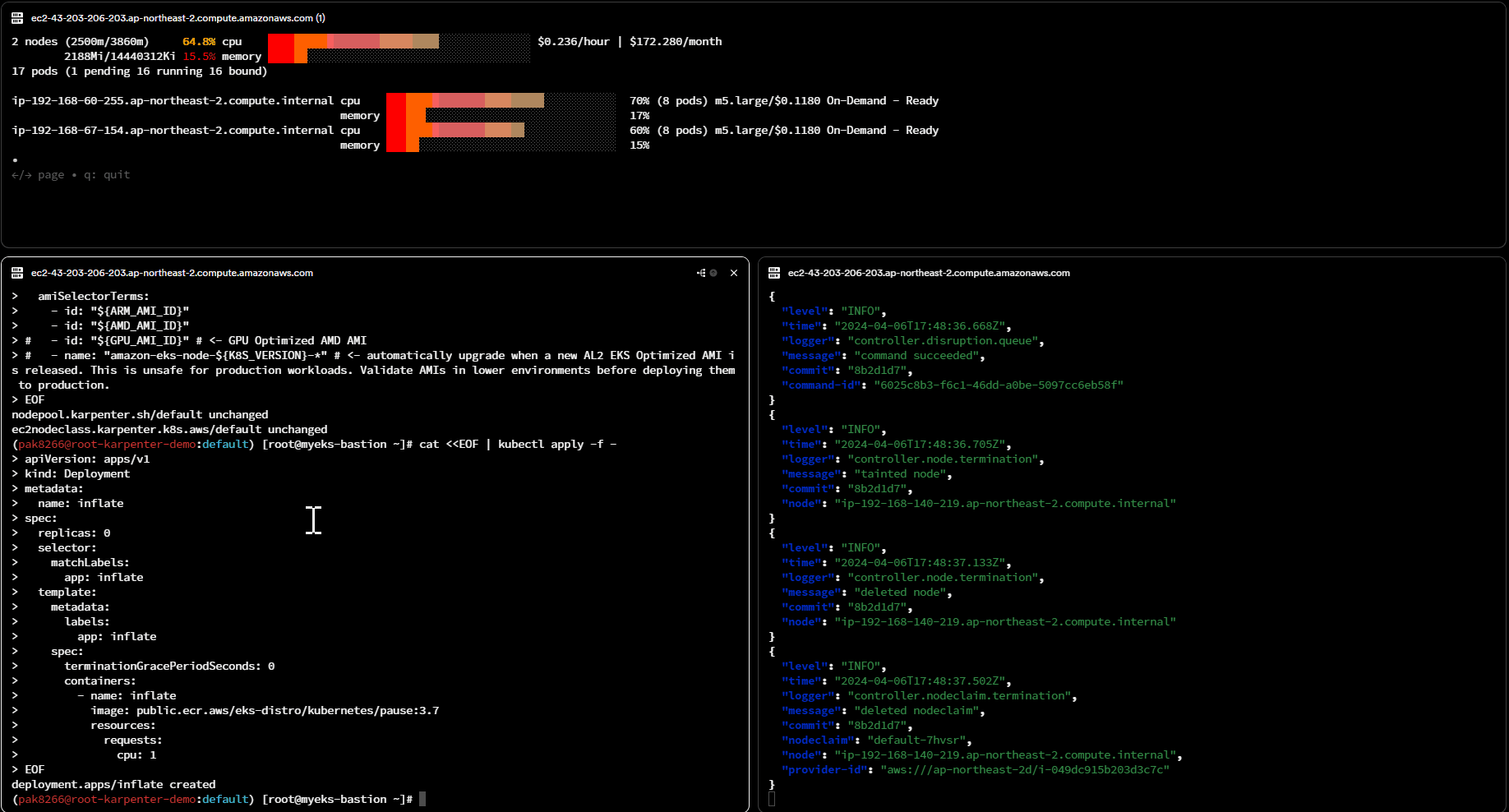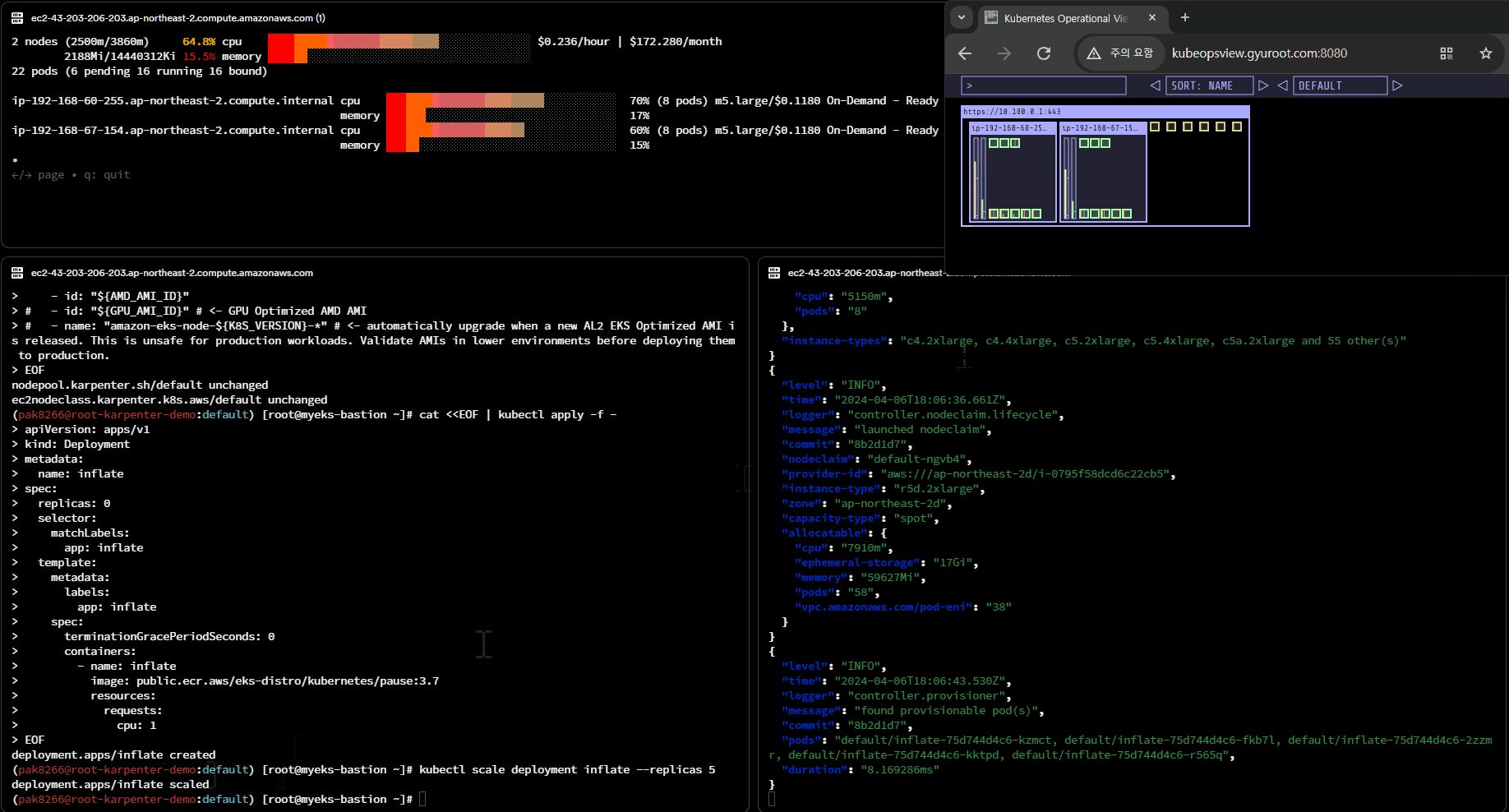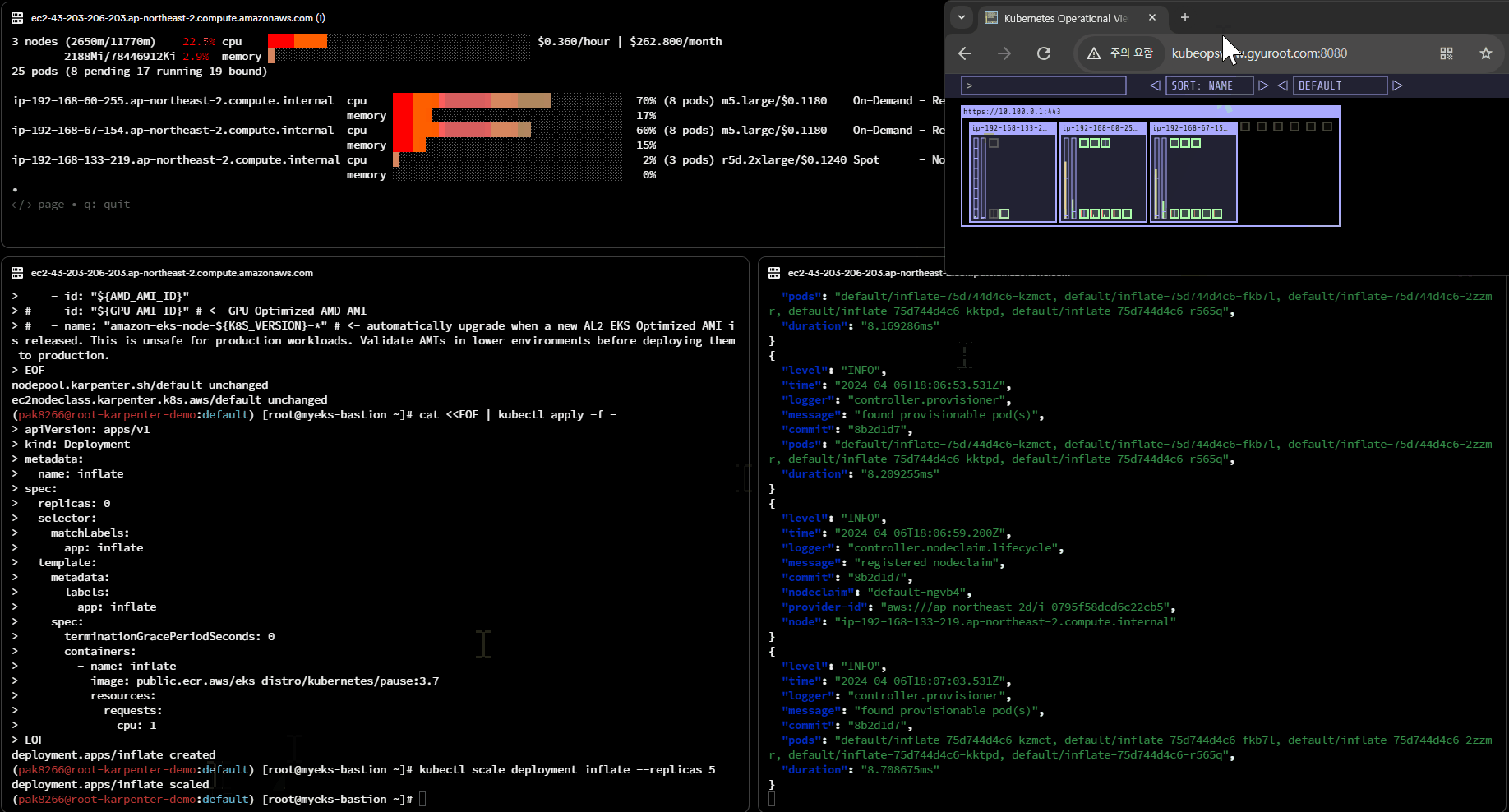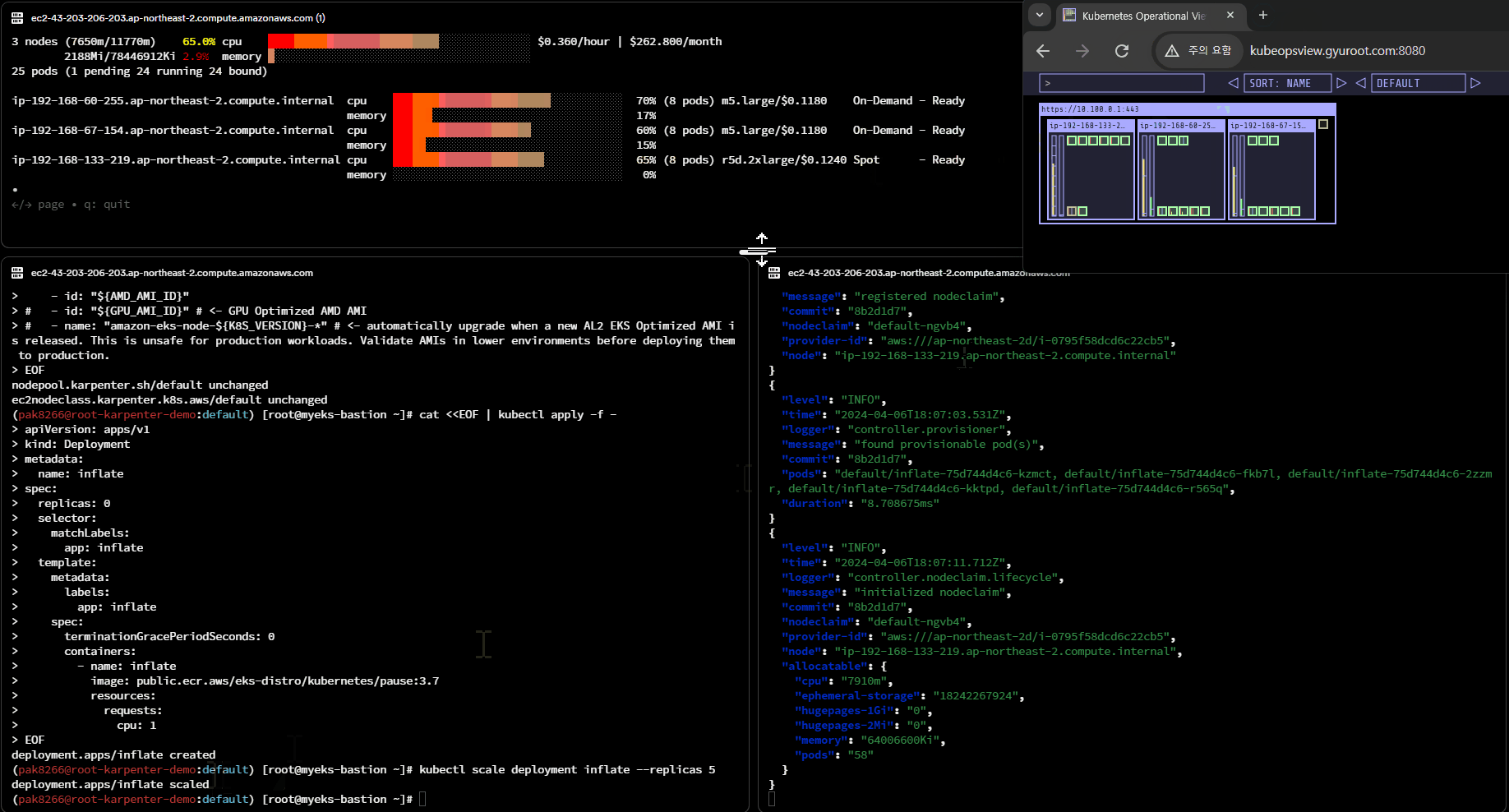
Karpenter 노드 생성 원리
- 자원 모니터링: Karpenter는 클러스터 내의 자원 상태를 모니터링합니다. 이는 CPU, 메모리, 스토리지 및 네트워크 리소스와 같은 클러스터의 자원 사용량을 실시간으로 추적하는 것을 의미합니다.
- 워크로드 분석: 클러스터에 새로운 Pod이 스케줄링될 때, Karpenter는 해당 Pod의 요구 사항을 분석합니다. 이는 Pod의 CPU 및 메모리 요구 사항, 가용 영역 및 리전에 대한 제약 사항 등을 고려합니다.
- EC2 Fleet 요청: 필요한 경우, Karpenter는 EC2 Fleet을 프로비저닝하기 위해 AWS에 요청을 보냅니다. 이 요청은 클러스터의 워크로드에 필요한 적절한 유형 및 크기의 EC2 인스턴스를 지정하고, 해당 인스턴스를 배치할 리전 및 가용 영역을 선택하는 것을 포함합니다.
- 구매 옵션 설정: EC2 Fleet을 프로비저닝할 때, Karpenter는 사용자가 지정한 구매 옵션을 설정합니다. 이는 인스턴스의 구매 유형(예: 예약 인스턴스, 온디맨드, 스팟 인스턴스) 및 인스턴스 유형 및 크기에 따라 결정됩니다.
- EC2 Fleet 프로비저닝: 설정이 완료되면, Karpenter는 AWS에 EC2 Fleet을 프로비저닝하도록 요청합니다. 이 요청은 AWS의 EC2 Fleet API를 사용하여 자동화되며, 클러스터의 워크로드에 필요한 인스턴스를 프로비저닝합니다.
- 노드 활성화 및 Pod 스케줄링: EC2 Fleet이 프로비저닝되면, Karpenter는 새로운 노드를 클러스터에 추가하고 활성화합니다. 이후 Kubernetes 스케줄러는 새로운 노드에 Pod을 배치하여 클러스터의 워크로드를 관리합니다.
Karpenter 적용 및 실습
- Karpenter Controller 설치
- Node 사양 정의하는 CRD 정의
- v0.32 이상 : NodePool, NodeClass
- v0.31 이하 : provisioner, Nodetemplate
참고 링크 : https://karpenter.sh/docs/
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
# Required, resolves a default ami and userdata
amiFamily: AL2
# Required, discovers subnets to attach to instances
# Each term in the array of subnetSelectorTerms is ORed together
# Within a single term, all conditions are ANDed
subnetSelectorTerms:
# Select on any subnet that has the "karpenter.sh/discovery: ${CLUSTER_NAME}"Create NodePool(구 Provisioner)
Disruption (구 Consolidation)