옵저버빌리티(observability)는 시스템의 내부 상태와 동작을 이해하고 추적할 수 있는 능력을 나타냅니다. 시스템의 상태, 이벤트 및 동작을 모니터링하고 디버깅하는 데 필요한 도구와 프로세스를 포함합니다. 옵저버빌리티를 향상시키기 위해서는 로깅(logging)이 중요한 구성 요소 중 하나입니다.
여러 이유로 옵저버빌리티를 강화하기 위해서 로깅이 필요합니다:
- 상태 추적: 로그는 시스템의 상태 변화를 기록합니다. 이를 통해 시스템이 어떻게 동작하고 있는지를 추적할 수 있습니다. 예를 들어, 애플리케이션의 시작, 중지, 오류 등의 이벤트를 로그에 기록하여 상태 변화를 추적할 수 있습니다.
- 이벤트 기록: 시스템에서 발생하는 이벤트를 로그에 기록함으로써 시스템의 동작을 추적할 수 있습니다. 예를 들어, 네트워크 요청, 데이터베이스 쿼리, 서비스 호출 등의 이벤트를 로그에 기록하여 추후 분석할 수 있습니다.
- 문제 해결: 시스템에서 발생하는 문제를 해결하기 위해서는 문제의 원인을 파악해야 합니다. 로그는 시스템에서 발생한 이벤트와 오류 메시지를 기록함으로써 문제를 해결하는 데 도움을 줍니다.
- 성능 분석: 시스템의 성능을 분석하고 최적화하기 위해서는 로그 데이터를 활용할 수 있습니다. 예를 들어, 서비스 응답 시간, 리소스 사용량 등의 지표를 로그에 기록하여 성능을 분석할 수 있습니다.
- 규정 준수: 로그는 보안 및 규정 준수를 위해 필요한 요구 사항 중 하나입니다. 예를 들어, PCI DSS, HIPAA 등의 규정은 로그 데이터의 수집, 보관 및 분석을 요구합니다.
EKS Logging Activate
EKS (Elastic Kubernetes Service)에서 로깅하는 주요 컴포넌트로는 다음과 같은 5가지가 있습니다:
- API Server Logs (API 서버 로그):
- Kubernetes API 서버에서 생성되는 로그입니다.
- 클러스터의 API 호출, 리소스 생성 및 수정 등의 활동을 기록합니다.
- 클러스터의 상태 및 동작을 추적하는 데 사용됩니다.
- Audit Logs (감사 로그):
- Kubernetes 클러스터에서 수행되는 작업에 대한 감사 이벤트를 기록하는 로그입니다.
- 클러스터의 보안 감사 및 규정 준수를 위해 사용됩니다.
- Authenticator Logs (인증기 로그):
- 인증 시스템에서 생성되는 로그입니다.
- 사용자 또는 서비스 계정의 인증 및 권한 부여 작업에 대한 정보를 기록합니다.
- 클러스터의 보안 및 접근 제어를 모니터링하는 데 사용됩니다.
- Controller Manager Logs (컨트롤러 관리자 로그):
- Kubernetes 컨트롤러 관리자에서 생성되는 로그입니다.
- 컨트롤러 관리자가 클러스터의 상태를 조정하고 관리하는 활동에 대한 정보를 기록합니다.
- 클러스터의 자동화 및 관리를 추적하는 데 사용됩니다.
- Scheduler Logs (스케줄러 로그):
- Kubernetes 스케줄러에서 생성되는 로그입니다.
- 스케줄러가 파드를 노드에 할당하고 관리하는 활동에 대한 정보를 기록합니다.
- 클러스터의 워크로드 관리와 리소스 할당을 추적하는 데 사용됩니다.
# aws-cli eks 로 로깅을 활성화하는 방법
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'Cloudwatch Log insights 쿼리
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
fields
@timestamp: 로그 이벤트의 발생 시간을 나타내는 필드입니다.@message: 로그 이벤트의 실제 메시지 내용을 나타내는 필드입니다.@logStream: 로그 이벤트가 발생한 로그 스트림의 이름을 나타내는 필드입니다.@logGroup: 로그 이벤트가 속한 로그 그룹의 이름을 나타내는 필드입니다.@ingestionTime: 로그 이벤트를 CloudWatch Logs에 인제스트한 시간을 나타내는 필드입니다.@requestId: CloudWatch Logs에 로그 이벤트를 전송한 요청의 ID를 나타내는 필드입니다.
filter
- 특정 필드 값의 비교:
filter 필드명 operator 값형식으로 사용합니다. 예를 들어,@message like /error/는@message필드에 “error”를 포함하는 로그를 필터링합니다. - 여러 조건의 결합:
AND,OR,NOT논리 연산자를 사용하여 여러 조건을 결합할 수 있습니다. - 정규 표현식 사용:
like연산자와 함께 정규 표현식을 사용하여 패턴을 지정할 수 있습니다.
sort
sort 필드명 [asc|desc]:asc는 오름차순(낮은 값에서 높은 값 순서)으로,desc는 내림차순(높은 값에서 낮은 값 순서)으로 정렬합니다. 기본적으로 내림차순으로 정렬됩니다.
Container Metric 수집
Fluent Bit
Fluent Bit은 경량의 오픈 소스 로그 수집 에이전트로서 다양한 환경에서 사용되며, 다음과 같은 장점을 갖고 있습니다:
- 경량 및 높은 성능: Fluent Bit은 경량이면서도 높은 성능을 제공합니다. 작은 바이너리 크기와 낮은 리소스 소비로 인해 컨테이너 및 서버에서 효율적으로 실행될 수 있습니다.
- 다양한 입력 및 출력 플러그인: Fluent Bit은 다양한 입력(input) 및 출력(output) 플러그인을 제공하여 다양한 데이터 소스로부터 로그를 수집하고, 다양한 목적지로 데이터를 전송할 수 있습니다. 이는 시스템 및 응용 프로그램 로그, 메트릭 등을 다양한 데이터 저장소로 전송하는 데 유용합니다.
- 유연한 구성 및 설정: Fluent Bit은 다양한 구성 및 설정 옵션을 제공하여 사용자가 로그 수집 및 전송 프로세스를 유연하게 구성할 수 있습니다. 필터링, 포맷 변환, 데이터 전처리 등을 지원하여 데이터를 효율적으로 처리할 수 있습니다.
- 클라우드 플랫폼 통합: Fluent Bit은 다양한 클라우드 플랫폼과 통합되어 있어 클라우드 환경에서 로그 수집 및 모니터링을 간편하게 구성할 수 있습니다. 예를 들어, AWS의 CloudWatch Logs와 함께 사용되어 AWS 환경에서 로그를 쉽게 수집하고 분석할 수 있습니다.
Fluent Bit을 사용하여 AWS의 CloudWatch Logs와 통합하는 경우, 다음과 같은 이점을 얻을 수 있습니다:
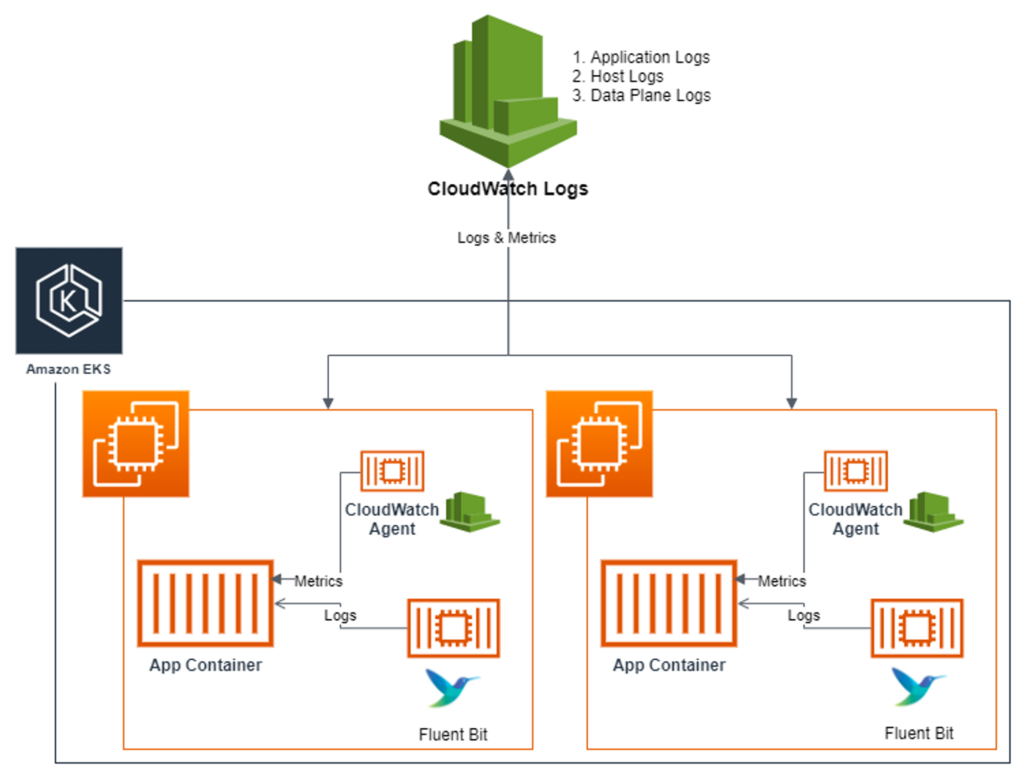
- 수집: Fluent Bit을 데몬셋(DaemonSet)으로 동작시키고 다양한 로그를 CloudWatch Logs로 전송할 수 있습니다. 클러스터 내의 애플리케이션 로그, 노드 로그, 쿠버네티스 데이터플레인 로그 등을 효과적으로 수집할 수 있습니다.
- /aws/containerinsights/
Cluster_Name/application : 로그 소스(All log files in/var/log/containers), 각 컨테이너/파드 로그 - /aws/containerinsights/
Cluster_Name/host : 로그 소스(Logs from/var/log/dmesg,/var/log/secure, and/var/log/messages), 노드(호스트) 로그 - /aws/containerinsights/
Cluster_Name/dataplane : 로그 소스(/var/log/journalforkubelet.service,kubeproxy.service, anddocker.service), 쿠버네티스 데이터플레인 로그
- /aws/containerinsights/
- 저장: CloudWatch Logs에 로그를 저장하고 로그 그룹 별로 로그 보존 기간을 설정할 수 있습니다. 이를 통해 로그 데이터를 안전하게 보관하고 필요에 따라 조회할 수 있습니다.
- 시각화: CloudWatch Logs Insights를 사용하여 로그를 분석하고, CloudWatch의 대시보드를 통해 로그를 시각화하여 클러스터 및 애플리케이션의 상태를 모니터링할 수 있습니다. 이를 통해 실시간으로 로그 데이터를 시각적으로 파악하고 문제를 신속하게 해결할 수 있습니다.
이와 같이 Fluent Bit과 CloudWatch Logs를 통합하여 로그 수집, 저장 및 시각화를 효과적으로 수행할 수 있습니다.
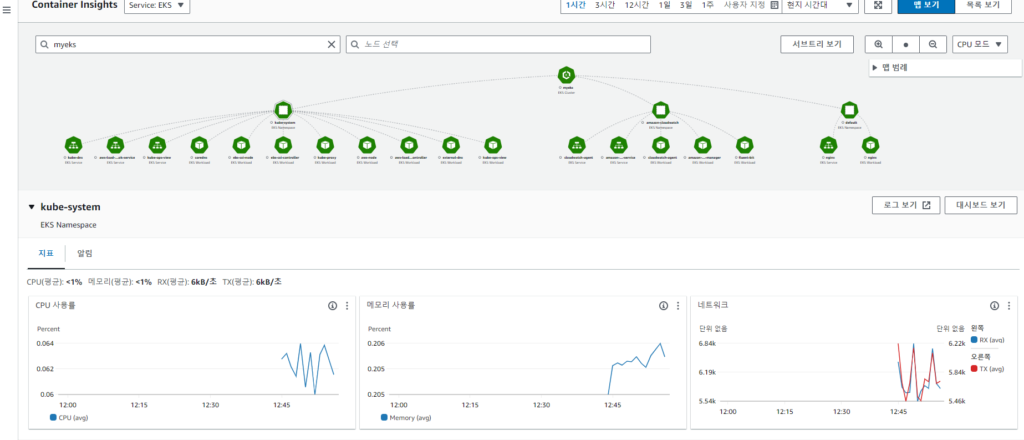
Container Insights
- 완전 관리형 서비스: Container Insights는 완전히 관리되는 서비스로, 사용자는 인프라 관리나 배포 과정에 대한 걱정 없이 컨테이너 기반 애플리케이션을 모니터링할 수 있습니다. AWS가 인프라 및 서비스 관리를 담당하여 사용자는 주로 애플리케이션의 상태 및 성능에 집중할 수 있습니다.
- 자동화된 대시보드 제공: Container Insights는 사용자에게 자동화된 대시보드를 제공하여 컨테이너 및 클러스터의 상태를 실시간으로 모니터링할 수 있습니다. 이를 통해 사용자는 손쉽게 애플리케이션의 상태를 파악하고 문제를 신속하게 해결할 수 있습니다.
- 실시간 모니터링 및 경고: Container Insights는 컨테이너 및 클러스터의 상태를 실시간으로 모니터링하고 사용자에게 경고를 제공합니다. 이를 통해 사용자는 시스템의 이상 상태를 신속하게 감지하고 조치를 취할 수 있습니다.
- 자동 클러스터 및 서비스 맵 구성: Container Insights는 컨테이너와 클러스터의 관계를 자동으로 파악하여 서비스맵을 구성합니다. 이를 통해 사용자는 컨테이너 간의 종속성 및 통신 패턴을 시각적으로 파악할 수 있습니다.
- 로그 분석 및 검색: Container Insights는 컨테이너 로그를 실시간으로 수집하고 분석하여 사용자에게 제공합니다. 이를 통해 사용자는 로그 데이터를 쿼리하여 원하는 정보를 검색하고 애플리케이션의 상태를 파악할 수 있습니다.
종합적으로, Container Insights는 사용자에게 완전히 관리되는 서비스를 제공하면서도 자동화된 대시보드와 실시간 모니터링 기능을 통해 컨테이너 기반 애플리케이션을 효율적으로 관리할 수 있는 특징을 가지고 있습니다.
CloudWatch 로깅 설정 확인 및 관리
- CloudWatch 로깅 애드온 설치
aws eks create-addon --cluster-name $CLUSTER_NAME --addon-name amazon-cloudwatch-observabilityaws eks list-addons --cluster-name myeks --output table
- 설치 확인
kubectl get-all -n amazon-cloudwatchkubectl get ds,pod,cm,sa,amazoncloudwatchagent -n amazon-cloudwatchkubectl describe clusterrole cloudwatch-agent-role amazon-cloudwatch-observability-manager-rolekubectl describe clusterrolebindings cloudwatch-agent-role-binding amazon-cloudwatch-observability-manager-rolebinding- CloudWatch 로그 파드의 로그 확인
kubectl -n amazon-cloudwatch logs -l app.kubernetes.io/component=amazon-cloudwatch-agent -f kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f
- CloudWatch Agent 설정 확인
kubectl describe cm cloudwatch-agent-agent -n amazon-cloudwatch

Fluent Bit 설정 확인
- Fluent Bit 파드 설정
- Fluent Bit이 로그를 수집하는 방식 확인:
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent - HostPath를 통해 로그를 수집하는 방식 검토:
ssh ec2-user@$N1 sudo tree /dev/disk
- Fluent Bit이 로그를 수집하는 방식 확인:
- Fluent Bit 설정 확인
- Fluent Bit 로그 입력(INPUT)/필터(FILTER)/출력(OUTPUT) 설정 확인:
kubectl describe cm fluent-bit-config -n amazon-cloudwatch
- Fluent Bit 로그 입력(INPUT)/필터(FILTER)/출력(OUTPUT) 설정 확인:
- Fluent Bit 파드가 수집하는 방식 검토
- HostPath를 통해 로그를 수집하는 방식 검토:
kubectl describe -n amazon-cloudwatch ds fluent-bit - 호스트 시스템의 로그 경로 확인:
ssh ec2-user@$N1 sudo tree /var/log
- HostPath를 통해 로그를 수집하는 방식 검토:
Metrics-server 배포 및 확인
- 배포
- metrics-server 배포:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
- metrics-server 배포:
- 메트릭 서버 확인
- 메트릭 서버 파드 확인:
kubectl get pod -n kube-system -l k8s-app=metrics-server - 사용 가능한 메트릭 리소스 확인 :
kubectl api-resources | grep metrics - API 서비스의 가용성 및 메트릭 확인 :
kubectl get apiservices | egrep '(AVAILABLE|metrics)'
- 메트릭 서버 파드 확인:
- 노드 및 파드 메트릭 확인
- 노드 메트릭 확인 :
kubectl top node - 파드 메트릭 확인 :
kubectl top pod -A kubectl top pod -n kube-system --sort-by='cpu' kubectl top pod -n kube-system --sort-by='memory'
- 노드 메트릭 확인 :
kwatch 소개, 설치 및 사용
- kwatch 설정
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
title: $NICK-EKS
#text: Customized text in slack message
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml프로메테우스를 이용한 모니터링 설정 및 배포
- 모니터링 네임스페이스 생성 및 감시
kubectl create ns monitoringwatch kubectl get pod,pvc,svc,ingress -n monitoring
- 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)echo $CERT_ARN
- Helm 저장소 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
#monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false- 배포
- 확인
helm list -n monitoringkubectl get pod,svc,ingress,pvc -n monitoringkubectl get-all -n monitoringkubectl get prometheus,servicemonitors -n monitoringkubectl get crd | grep monitoringkubectl df-pv
AWS CNI Metrics 수집을 위한 사전 설정
# podmonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-nodePodMonitor 확인 및 AWS CNI 메트릭 수집
- PodMonitor 확인
kubectl get podmonitor -n kube-systemkubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat | yh
- PodMonitor 설정
- 메트릭 수집 설정:
- 작업 레이블:
k8s-app - 네임스페이스 선택기:
kube-system - 파드 메트릭 엔드포인트:
- 경로:
/metrics - 포트:
metrics
- 경로:
- 셀렉터:
k8s-app: aws-node
- 작업 레이블:
- 메트릭 수집 설정:
- 메트릭 URL 접속 확인
curl -s $N1:61678/metrics | grep '^awscni'
ServiceMonitor:
- 목적: 서비스 레벨에서 메트릭을 수집하고 모니터링합니다.
- 설정: 서비스를 대상으로 하며, 해당 서비스가 제공하는 모든 엔드포인트의 메트릭을 수집합니다.
- 대상: 서비스 레벨에서 모니터링할 때 사용됩니다. 여러 파드를 통해 동일한 서비스를 제공하는 경우에 유용합니다.
- 예시: 서비스 메트릭, HTTP 엔드포인트 메트릭 등을 수집하는 데 사용됩니다.
PodMonitor:
- 목적: 파드 레벨에서 메트릭을 수집하고 모니터링합니다.
- 설정: 개별 파드를 대상으로 하며, 파드의 특정 포트 및 경로에서 메트릭을 수집합니다.
- 대상: 파드 레벨에서 모니터링할 때 사용됩니다. 서비스보다 더 세부적인 모니터링이 필요한 경우에 유용합니다.
- 예시: 개별 파드가 제공하는 메트릭, 특정 포트 또는 경로의 HTTP 엔드포인트 메트릭 등을 수집하는 데 사용됩니다.
Prometheus Query
Node exporter
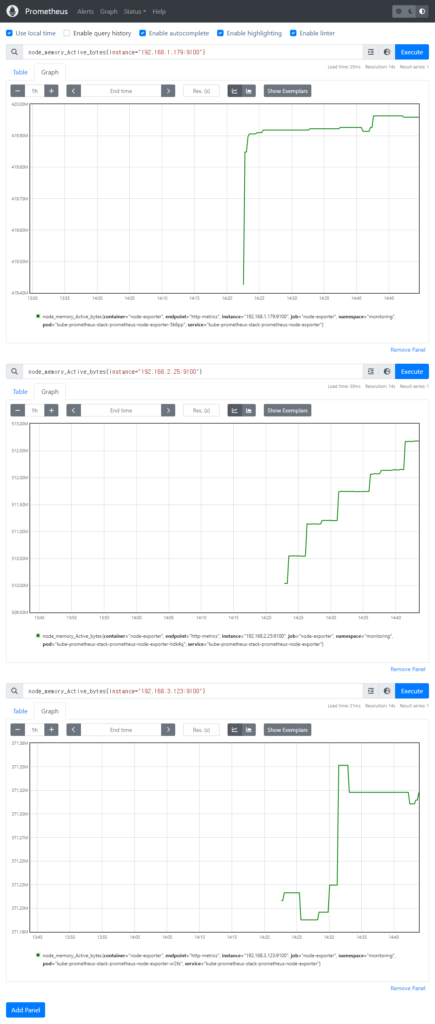
node-exporter는 리눅스 머신 또는 다른 UNIX 계열 시스템에서 실행되는 에이전트입니다. 이 에이전트는 해당 시스템의 여러 가지 리소스 및 성능 메트릭을 수집하여 프로메테우스 서버에 노출합니다. 주로 서버 또는 가상 머신의 운영 체제와 관련된 메트릭을 수집하며, 시스템 리소스 사용률, CPU 사용량, 메모리 사용량, 디스크 공간 사용량, 네트워크 트래픽 등과 같은 정보를 수집합니다.
node-exporter는 프로메테우스가 시스템 리소스 및 성능을 모니터링할 수 있도록 도와줍니다. 프로메테우스는 node-exporter를 통해 수집된 메트릭을 저장하고 쿼리할 수 있으며, 이를 통해 사용자는 각 서버 또는 머신의 상태를 모니터링하고 문제를 진단할 수 있습니다.
주요 기능은 다음과 같습니다:
- 시스템 리소스 메트릭 수집: CPU, 메모리, 디스크, 네트워크 등과 같은 시스템 리소스에 대한 다양한 메트릭을 수집합니다.
- 프로메테우스와의 통합: node-exporter는 프로메테우스의 클라이언트로 동작하여 수집된 메트릭을 프로메테우스 서버에 노출합니다.
- 간편한 설치 및 구성: 다양한 운영 체제와 환경에서 쉽게 설치하고 설정할 수 있습니다.
- 확장성: 여러 노드에서 실행되는 여러 인스턴스를 통해 대규모 시스템에서도 사용 가능합니다.
은 일반적으로 프로메테우스(예: node-exporter)나 다른 모니터링 에이전트에서 사용되는 포트입니다.
node-exporter는 각 노드에서 시스템 및 하드웨어 메트릭을 수집하고 프로메테우스 형식으로 노출하는 역할을 합니다. 기본적으로 node-exporter는 포트 9100에서 메트릭을 노출하며, 프로메테우스 서버는 이 포트를 통해 node-exporter로부터 메트릭을 수집합니다.
kube_state-metrics
kube_deployment_status_replicas_available는 쿠버네티스에서 사용되는 Prometheus 메트릭 중 하나입니다. 이 메트릭은 쿠버네티스에서 배포된 애플리케이션의 상태를 모니터링하는 데 사용됩니다.
이 메트릭은 쿠버네티스 배포(Deployment) 오브젝트의 현재 사용 가능한 파드(replicas)의 수를 나타냅니다. 배포 오브젝트는 파드를 관리하며, 일정한 수의 파드를 유지하기 위해 필요한 파드의 복제본(replicas) 수를 지정할 수 있습니다.
따라서 kube_deployment_status_replicas_available 메트릭은 배포된 애플리케이션의 현재 가용한 파드 수를 나타내며, 이를 통해 애플리케이션의 상태를 모니터링하고 필요에 따라 조치를 취할 수 있습니다. 만약 이 메트릭이 원하는 수준보다 낮다면, 해당 배포의 파드가 충분히 실행되지 않았거나 문제가 발생한 것으로 간주할 수 있습니다.

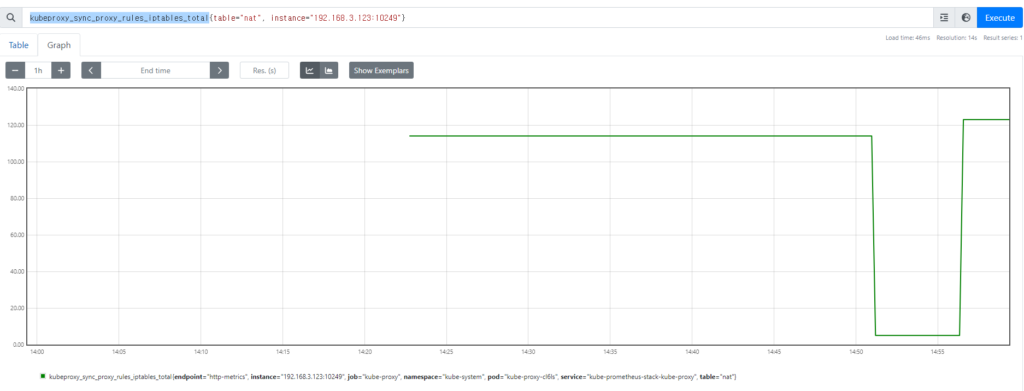
kube-proxy
kubeproxy_sync_proxy_rules_iptables_total은 쿠버네티스(Kubernetes)의 네트워크 프락시(Kube-proxy) 컴포넌트에서 관리되는 iptables 규칙의 동기화 횟수를 측정하는 Prometheus 메트릭 중 하나입니다.
Kube-proxy는 쿠버네티스 클러스터 내부에서 서비스 디스커버리와 로드 밸런싱을 수행하는데 사용됩니다. 이러한 기능을 위해 Kube-proxy는 네트워크 트래픽을 적절한 파드로 라우팅하기 위한 iptables 규칙을 관리합니다. 예를 들어, 서비스의 클러스터 IP를 노출하기 위해 iptables 규칙을 생성하거나, 로드 밸런싱을 위해 iptables NAT 규칙을 설정합니다.
kubeproxy_sync_proxy_rules_iptables_total 메트릭은 Kube-proxy가 iptables 규칙을 동기화한 횟수를 나타냅니다. 이 메트릭을 통해 Kube-proxy의 동작 상태를 모니터링하고, iptables 규칙이 적절하게 관리되고 있는지 확인할 수 있습니다. 예를 들어, 이 메트릭이 지속적으로 증가하는 경우, Kube-proxy가 정상적으로 동작하고 있는지 확인할 수 있습니다.
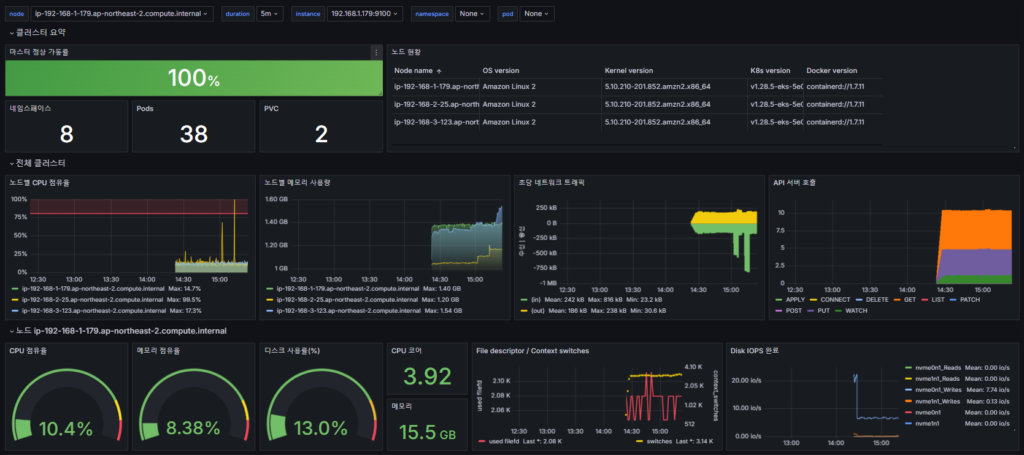
Grafana
Grafana는 오픈 소스 시각화 및 모니터링 도구로, 메트릭, 로그 및 트레이스와 같은 다양한 데이터 형식을 지원합니다. 이 도구는 사용자가 저장된 데이터를 쿼리하고 이를 그래프, 대시보드, 경고 및 탐색을 통해 시각화할 수 있도록 합니다. Grafana는 다양한 데이터 소스와 통합되어 있어서, 여러 데이터 소스에서 데이터를 가져와 통합된 시각화를 제공할 수 있습니다.
- 다양한 데이터 소스 지원: Grafana는 다양한 데이터 소스를 지원하며, Prometheus, InfluxDB, Elasticsearch, MySQL, PostgreSQL 등의 데이터베이스 및 다양한 클라우드 서비스와 통합할 수 있습니다.
- 강력한 대시보드: 사용자는 Grafana를 사용하여 사용자 정의 대시보드를 만들고 다양한 차트, 그래프, 테이블 등을 추가하여 시스템의 상태를 시각적으로 파악할 수 있습니다.
- 경고 및 알림: Grafana는 사용자가 설정한 조건에 따라 경고를 생성하고 이를 이메일, Slack 등과 같은 다양한 방법으로 알림을 보낼 수 있습니다.
- 탐색 및 쿼리: Grafana는 사용자가 데이터를 탐색하고 쿼리할 수 있는 강력한 도구를 제공합니다. 사용자는 PromQL, SQL 및 Lucene 쿼리를 사용하여 데이터를 필터링하고 분석할 수 있습니다.
- 확장성과 커스터마이징: Grafana는 플러그인 아키텍처를 통해 사용자가 시스템을 확장하고 사용자 정의 기능을 추가할 수 있도록 지원합니다. 사용자는 커뮤니티에서 다양한 플러그인을 찾아서 Grafana를 사용자의 요구에 맞게 확장할 수 있습니다.
그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
대시보드 구성
기본 대시보드
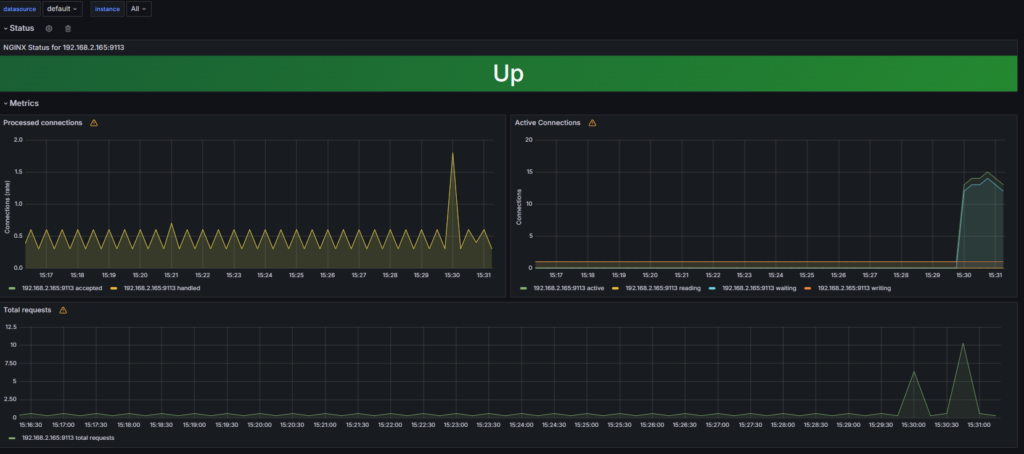
애플리케이션(nginx) 대시보드 구성 모니터링 진행
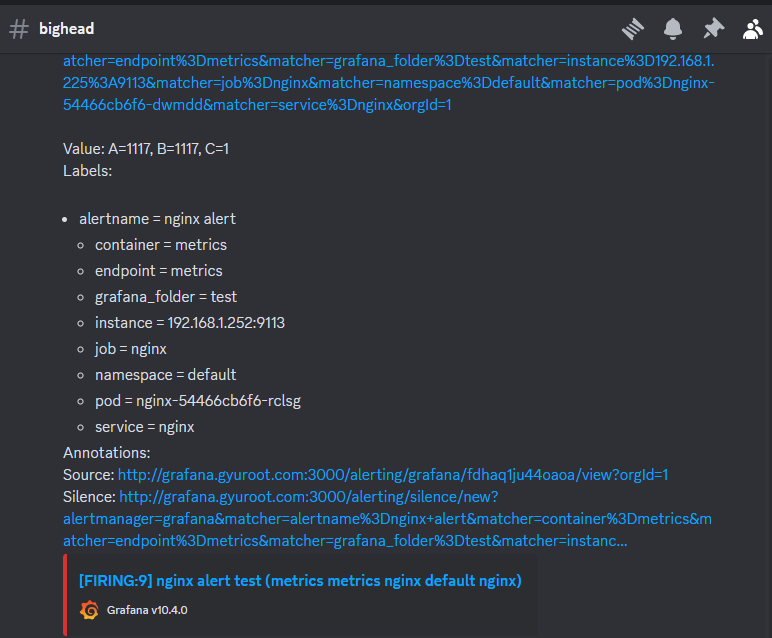
Grafana 에서 Alert 기능 사용하기
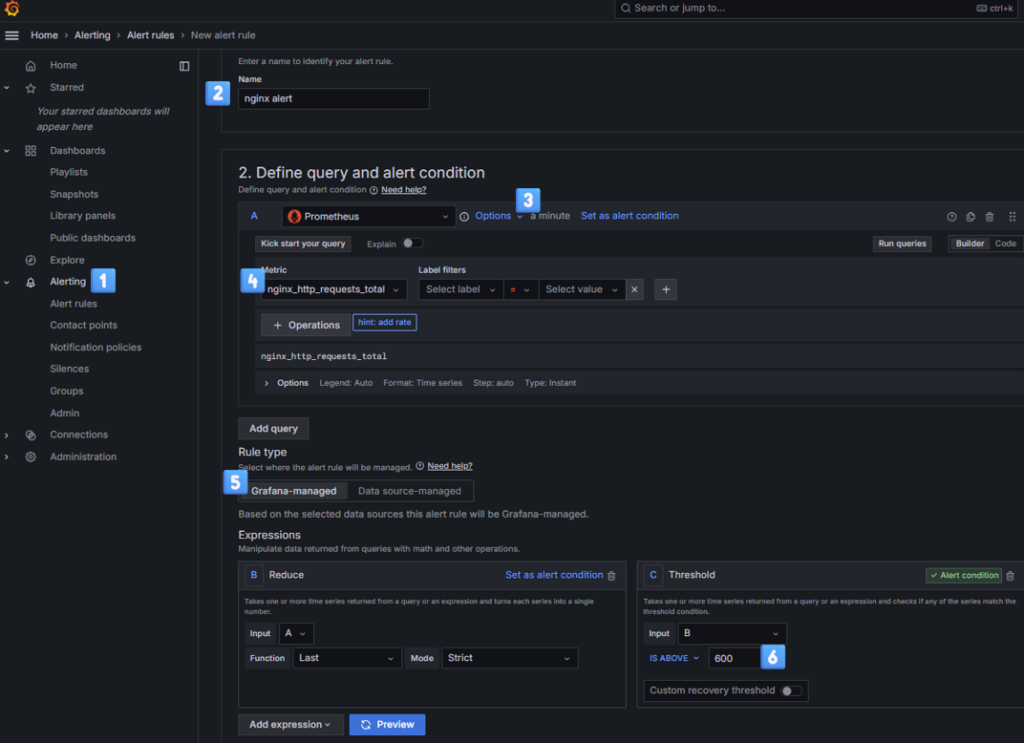
- 웹훅 메세지 확인
kubecost
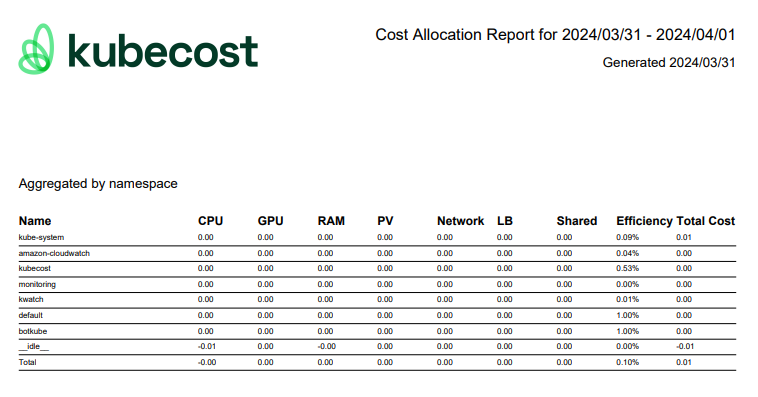
Kubecost는 쿠버네티스(Kubernetes) 환경에서 발생하는 클라우드 비용을 관리하고 최적화하는 데 도움을 주는 툴이자 서비스입니다. Kubecost는 클라우드 리소스의 비용을 투명하게 시각화하고, 리소스를 효율적으로 사용하도록 지원하여 비용을 절감하고 예산을 관리할 수 있게 해줍니다.
주요 기능과 장점은 다음과 같습니다:
- 리소스 비용 시각화: Kubecost는 쿠버네티스 클러스터에서 사용되는 리소스(예: CPU, 메모리, 스토리지)의 비용을 시각화하여 사용량 및 비용을 쉽게 파악할 수 있습니다. 클러스터, 네임스페이스, 애플리케이션별 비용 분석을 제공합니다.
- 비용 예측: Kubecost는 현재 및 예상 비용을 기반으로 리소스 비용에 대한 예측을 제공하여 비용을 최적화하는 데 도움을 줍니다.
- 비용 중심 리소스 관리: Kubecost는 리소스 사용량을 비용 중심으로 관리하고, 비용이 많이 발생하는 리소스를 식별하여 비용을 절감할 수 있는 방법을 제안합니다.
- 알림 및 경고: Kubecost는 예산을 초과하는 경우나 잠재적인 비용 증가에 대한 알림 및 경고를 제공하여 프로액티브한 비용 관리를 할 수 있게 해줍니다.
- 통합: Kubecost는 Prometheus, Grafana, Slack 등과 같은 다양한 툴과 통합되어 있어 쿠버네티스 클러스터의 비용을 모니터링하고 관리하는 데 유용합니다.
kubecost 대시보드 및 보고서