

프로젝트 소개
✅ 자산 관리 시스템을 도입하게 된다면 이 시스템을 어떻게 운영 및 보안 계획을 수립할것인가
많은 기업들이 각종 시스템과 IT 자산을 효율적으로 관리할 필요성이 커지고 있으며 이를 효율적으로 관리하기 위한 최적의 관리방법으로 EAM(Enterprise Asset Management), ITAM(IT Asset Management) 등 여러가지 관리 시스템을 운용을 하고 있습니다.
하지만 미흡한 보안 정책 및 절차로 인한 피해사례가 있었으며 그에 따른 해결방안으로 아래의 기사를 참고하여 중요성을 알게 되었습니다.
“자산관리 플랫폼으로 공격자 침투 가능성 낮춰야”
국내 주요 기업과 기관을 공격했던 매스스캔 랜섬웨어는 취약점이 있는 노출된 DB 서버를 파괴하면서 피해조직의 서비스를 중단시켰다.
……
포괄적인 IT 자산 인벤토리는 만들고 유지 관리하기 어렵다. 인벤토리 구축을 위한 기존의 많은 방법은 시간이 많이 걸리고 단편적이며 최신 상태를 유지하기 어렵다.
따라서 공격 표면 영역을 정의할 때 데이터 수집 및 상관 관계를 자동화하고, 부담스러운 인력 리소스 투입을 최소화하며, 실시간 결과를 위해 지속적으로 실행할 수 있는 사이버 보안 자산 관리 플랫폼을 사용하고 있는지 확인할 수 있는 방안을 강구해야 한다.
출처 : 데이터넷 – 2023.02.03
프로젝트 목표
- 자산 분류 기준에 따라 수립된 정의 및 리소스에 적절한 Tag 설정
- 자산이 많아질수록 관리의 복잡도를 완화하기 위해 각 리소스를 식별할 수 있어야 하며 그룹화 할 수 있어야 합니다.
- 정보 자산 점검
- MITRE 에서 제공하는 보안 기준인 CCE 및 CVE 취약점을 점검하고 위협을 제거 할 수 있어야 합니다.
- 모니터링 및 알람
- 리소스에서 Metric과 Log를 수집하고 시각화 할 수 있어야 합니다.
- 수집한 데이터로 예기치 못한 상황의 알람과 매일 점검한후의 보고서를 확인 할 수 있어야 합니다.
- 자동화
- 단순 반복적인 작업은 자동화 할 수 있어야 하며 인프라 전반의 CI/CD 파이프라인이 구성되어야 합니다.
프로젝트 인프라 요구사항
- 시스템 전반에 가용성, 내결함성, 확장성, 보안성이 고려된 서비스들이 포함되어야 합니다.
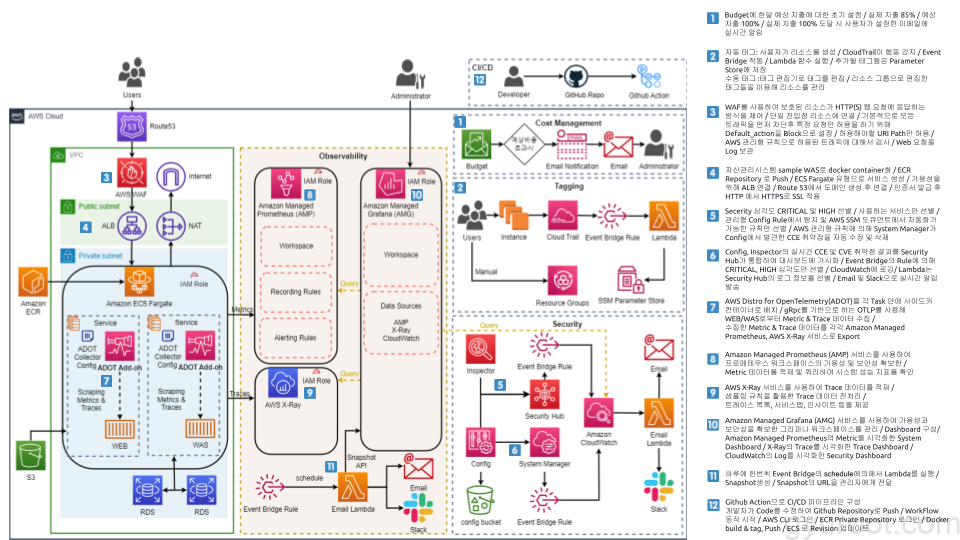
프로젝트 진행
✅ 프로젝트는 총 5명이서 16일동안 (2023-06-12 ~ 27) 진행되었고 AWS에서 구성되었습니다.
자산관리시스템의 개발과정이 아닌 운영과 보안 그리고 모니터링에 초점을 두었습니다.
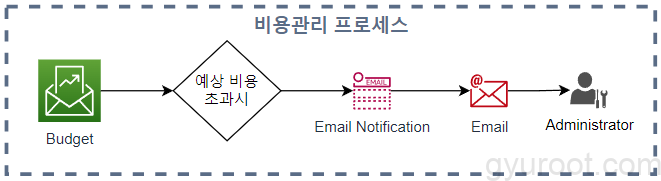
비용관리 프로세스
- AWS Budget 서비스를 이용하여 예상치 못한 지출을 사전에 방지합니다.
- 실제 지출이 85%에 도달할 경우
- 실제 지출이 100%에 도달할 경우
- 예상 지출이 100%에 도달할 경우
리소스 태깅 프로세스
- 자동 태깅 프로세스
- 사용자가 사용하는 계정에 리소스가 추가되면 자동으로 태그를 추가하도록 구현합니다.
- 추가 할 태그 정보는 SSM Parameter Store에서 참조합니다.
- 수동 태깅 프로세스
- AWS Resource Group에서 Tag Editor를 이용하여 태그를 추가합니다.

💡 Cloud Trail 이란? AWS 계정의 운영 및 위험 감사, 거버넌스 및 규정 준수를 활성화하는 데 도움이 되는 AWS 서비스 사용자, 역할 또는 AWS 서비스가 수행하는 작업들은 CloudTrail에 이벤트로 기록됩니다.
Sample System 생성
Create Code [Repository]
- X-Ray Trace 및 Prometheus Metric 수집을 위한 간단한 WAS Code 작성
- domain.com/user 로 요청후 순차적으로 다른 WAS 호출
- user -> course -> content 순으로 호출하며 구간별로 Trace 생성하도록 개발

Elastic Container Repository
- Private Repository 생성 후 docker image push
Elastic Container Service
WAS 컨테이너화 : user, content, course
- 각각 API 별로 서비스를 생성하며 생성한 서비스는 3개입니다.
- 시스템 전반에 가용성과 확장성을 고려하여 ECS유형중 FARGATE로 서비스를 구현하였습니다.
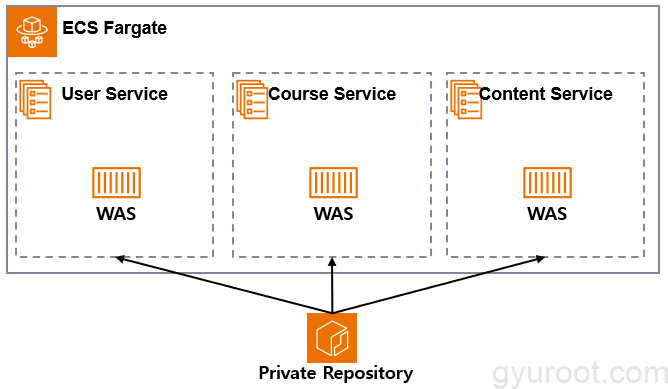
서비스
- 많은 요청을 분산시켜줄 Load Balancer 사용
- 도메인 설정
- 인증서 발급 후 HTTP 요청을 암호화하기 위한 SSL 적용
- AWS-Otel-collector-image를 pull하기 위해 NAT 설정을 진행
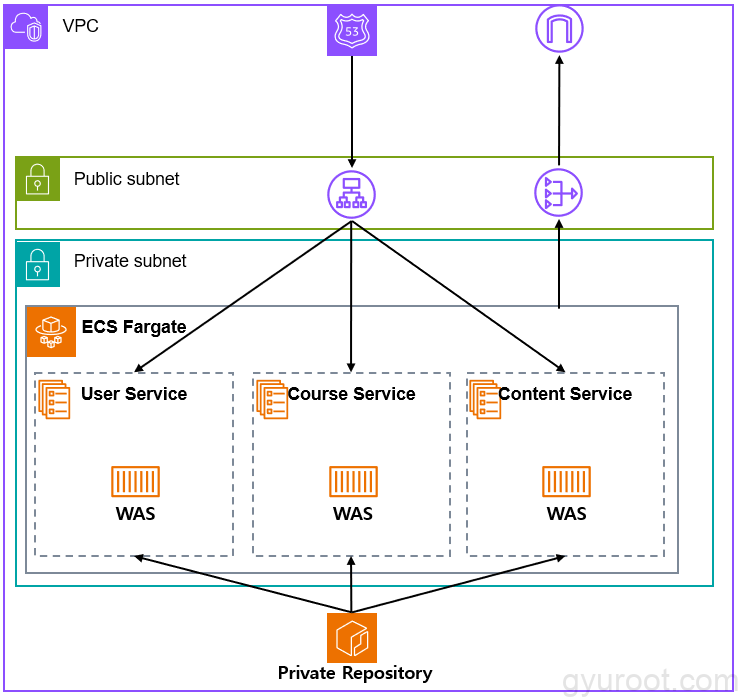
WAF(Web Application Firewall) 구성
- WAF리소스를 최상단에 위치한 이유는 최종 애플리케이션 방화벽이며 WAF를 사용하여 보호된 리소스가 HTTP (S) 웹 요청에 응답하는 방식을 제어할 수 있습니다.
- ACL (웹 액세스 제어 목록) 을 정의한 다음 보호하려는 next-hop인 Application Load Balancer를 연결했습니다.
- 기본적으로 모든 트래픽을 먼저 차단후 특정 요청만 허용을 하기 위해 Default_action을 Block으로 설정
- WAS API인 /user, /content, /was 경로에만 허용처리
- 허용처리된 요청중에 악성행위가 있는지 검사하기 위한 관리형 규칙 설정
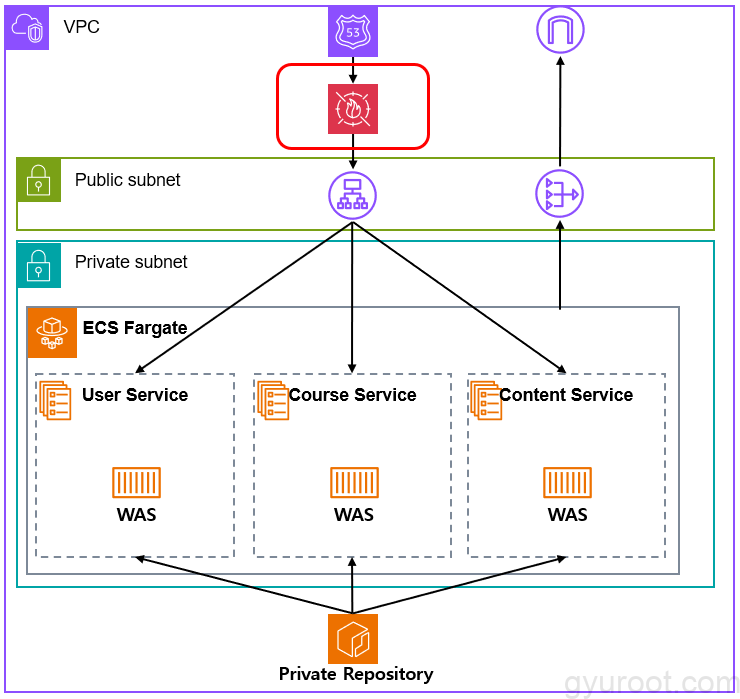
💡 웹 ACL에서 1,500개 이상의 WCU를 사용하면 기본 웹 ACL 가격을 초과하는 비용이 발생하기 때문에 1,500개 이하로 설정하였습니다. (참고로 규칙 그룹의 최대 용량은 5,000WCU입니다.) WAF는 기본값으로 Logging하고 있지 않습니다. 따라서 CloudWatch나 S3, Kinesis Data Firehos stream으로 내보내지 않는 이상 Sample Request Data로 있으며 보관기한은 3시간입니다.
AWS 관리형 규칙
- AWS-AWSManagedRulesAmazonIpReputationList
- Amazon IP 평판 목록을 사용하여 웹 요청의 IP 주소를 평가하고, 악성 행위가 의심되는 IP 주소에서의 액세스를 차단
- AWS-AWSManagedRulesAnonymousIpList
- 익명 프록시 및 VPN 서비스와 관련된 IP 주소 목록을 사용하여 익명 사용자의 액세스를 제한
- AWS-AWSManagedRulesCommonRuleSet
- 일반적으로 알려진 웹 어플리케이션 취약성과 관련된 공격을 차단
- AWS-AWSManagedRulesKnownBadInputsRuleSet
- 알려진 악성 입력값과 관련된 웹 어플리케이션 공격을 탐지하고 차단
- AWS-AWSManagedRulesLinuxRuleSet Use rule actions
- Linux 서버와 관련된 취약성 및 공격 패턴을 탐지하여 보호
- AWS-AWSManagedRulesSQLiRuleSet
- SQL 삽입(SQL Injection) 공격을 탐지하고 차단하는 역할
적용 후 기대 효과
- 서비스 하고있는 URI Path에 대한 요청만 허용
- HTTP User-Agent 헤더가 누락된 요청을 검사 후 차단
- 2,048바이트가 넘는 URI 쿼리 문자열을 검사 후 차단
- 10,240바이트가 넘는 쿠키 헤더를 검사 후 차단
- 8KB (8,192바이트) 를 초과하는 요청 본문을 검사 후 차단
- 1,024바이트가 넘는 URI 경로를 검사 후 차단
../../같은 기술을 사용한 경로 탐색 시도 차단 후 차단- 일반적인 크로스 사이트 스크립팅 (XSS) 패턴에 대한 쿠키 헤더 값을 검사
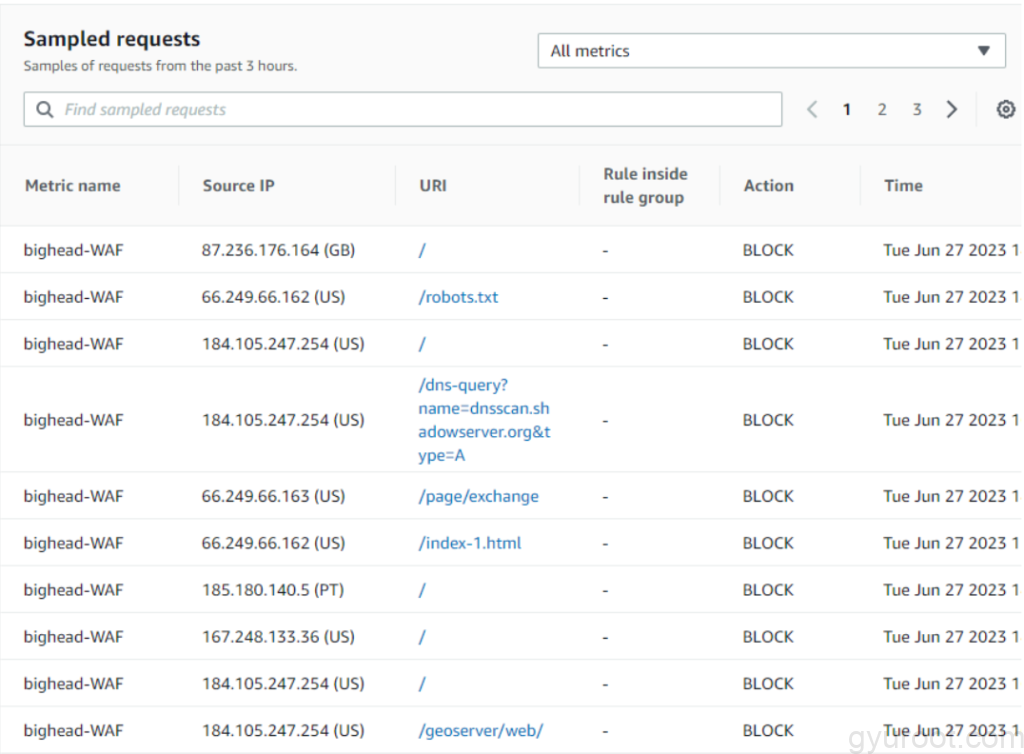
적용 후 Test
- 테스트한 Request 데이터 샘플이며 /user, /content, /course 를 제외한 나머지는 BLOCK처리가 되는것을 확인할 수 있습니다.
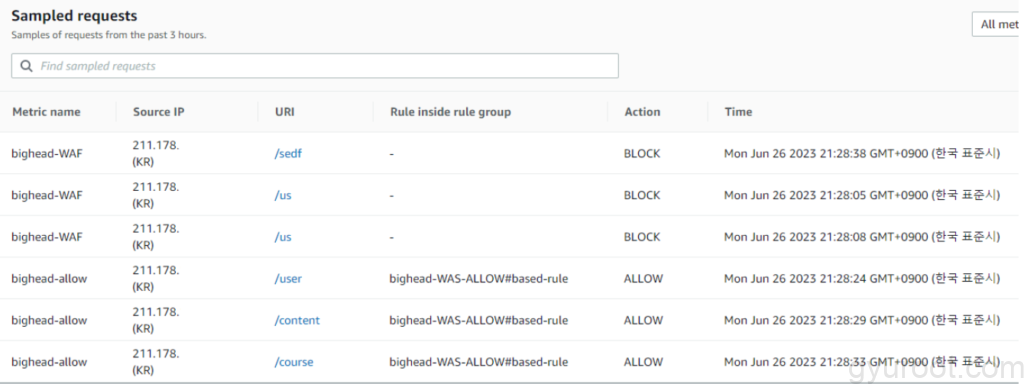
- 실제로 공격시도가 있었던 Request Sample
- Root directory를 접근한 공격시도
- robots.txt로 접근하여 검색엔진에 노출을 시키려는 공격시도
- 다른 URI Path로의 접근을 차단한것을 볼 수 있습니다.
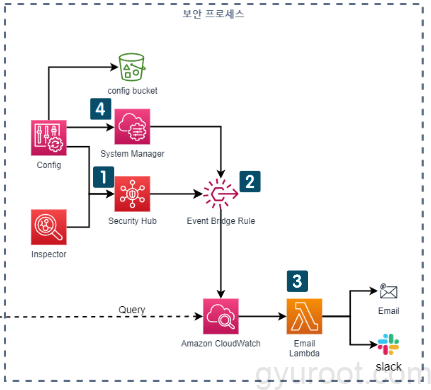
보안 프로세스
- Inspector, Config의 실시간 결과를 Security Hub로 라우팅
- Security Hub로 라우팅 된 결과를 Event Bridge Rule을 사용해 CloudWatch로 전달
- CloudWatch가 트리거가 되어 Lambda 함수가 Email과 Slack으로 실시간 취약점 알림 전달
- System Manager를 통하여 Config의 AWS 관리형 규칙에 의해 CCE 취약점 수정 자동화
💡 서비스 간단 설명 AWS Config AWS 리소스의 구성 변경 사항을 추적하고 모니터링하여 정책 준수, 보안, 운영 최적화 등을 위한 자동화된 구성 관리 서비스입니다. AWS Inspector AWS 리소스에 대한 보안 취약점을 자동으로 검사하고, 보안 관련 규정 및 권장 사항을 준수하는 데 도움을 주는 서비스입니다. AWS Security Hub 다양한 AWS 계정 및 서비스에서 보안 관련 이벤트와 알림을 중앙 집중화하여 제공하고, 보안 관련 취약성 및 위협에 대한 종합적인 시각을 제공하는 통합 보안 관리 서비스입니다. AWS System Manager AWS 클라우드 리소스의 운영 및 관리를 통합적으로 제어하고, 자동화된 운영 작업, 시스템 보안 관리, 자원 인벤토리 추적 등 다양한 운영 작업을 수행할 수 있는 관리 서비스입니다.
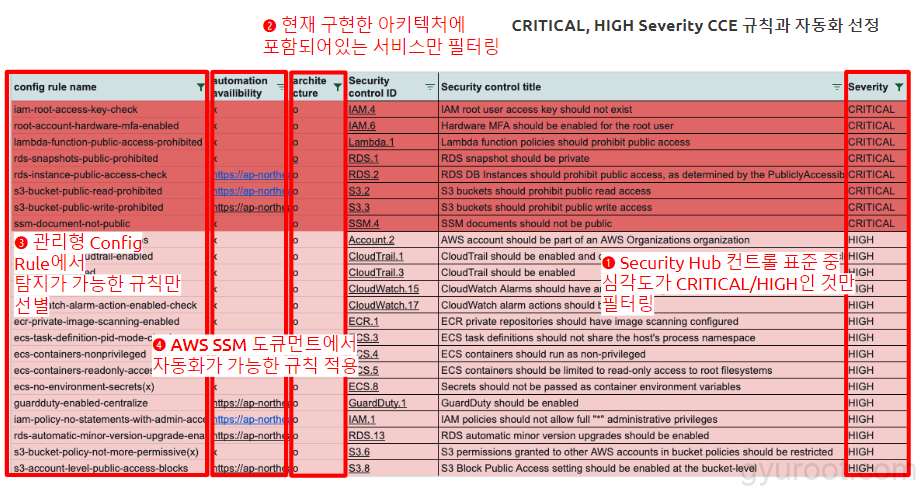
AWS Config Rule 설정
- 아키텍처 상에서 탐지가 가능한 AWS 관리형 규칙만 선별했습니다.
- 보안사항 미준수 리소스중에서 준수할 수 있도록 자동화가 가능한 부분은 규칙을 적용하였습니다.
보안 프로세스 구현 결과
- 보안사항 미준수 프로세스가 발견되면 Slack이나 메일로 알림을 할 수 있도록 구현했습니다.
- 취약점 알림
- 취약점 정보
- 취약점 발생 리소스
- 취약점 현황
- 취약점 상세정보

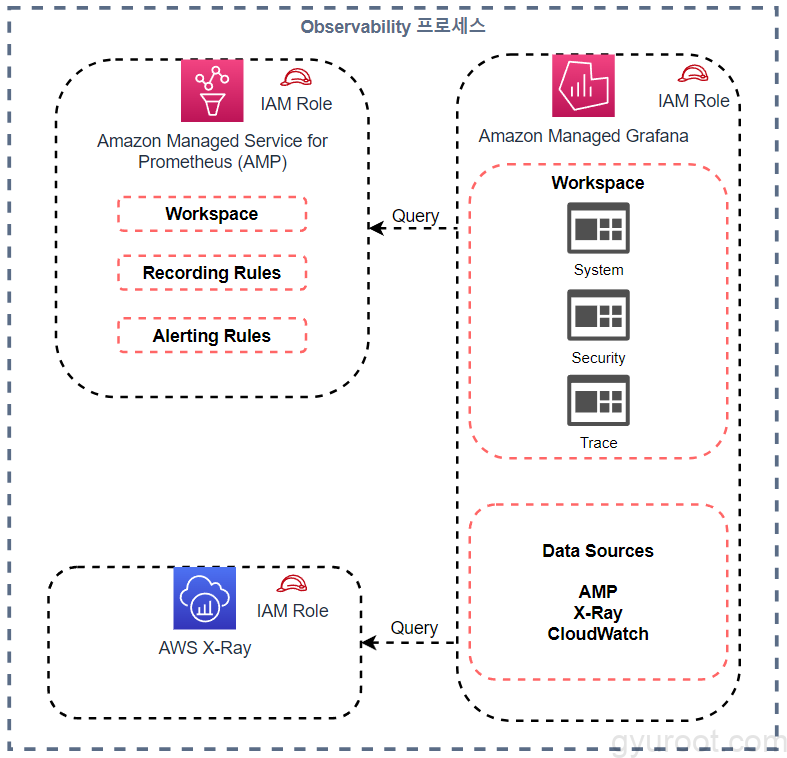
Observability 프로세스
✅ 사용한 Observability 사용 도구 중 오픈 소스인 Opentelemetry를 사용했습니다. Opentelemetry는 애플리케이션 성능 모니터링과 디버깅을 위한 표준화된 API와 라이브러리를 제공하여 분산 시스템에서의 추적, 로그 및 메트릭 수집을 가능하게 합니다. 이를 통해 애플리케이션의 동작을 실시간으로 모니터링하고, 문제를 진단하며 최적화하는 데 도움이 됩니다.
Vendor 중립성
- Opentelemetry는 벤더에 종속되지 않으며, 다양한 클라우드 공급자나 모니터링 도구와 통합할 수 있습니다. 이는 사용자가 자유롭게 선택한 벤더나 도구를 사용하여 애플리케이션의 Observability를 관리할 수 있음을 의미합니다.
다양한 언어와 프레임워크 환경에서 작동하는 범용성
- Opentelemetry는 다양한 언어와 프레임워크 환경에서 사용할 수 있는 범용적인 API와 라이브러리를 제공합니다. 이는 개발자들이 자신의 선호하는 언어와 프레임워크를 사용하여 Opentelemetry를 쉽게 통합할 수 있음을 의미합니다.
데이터 수집과 처리의 유연성
- Opentelemetry는 한 번에 수집한 데이터를 여러 가지 방식으로 처리하고 다양한 백엔드로 전달할 수 있습니다. 이는 실시간 분석, 저장, 모니터링, 알림 등 다양한 용도로 데이터를 활용할 수 있음을 의미합니다.
확장성
- Opentelemetry는 대규모 시스템 및 분산 환경에서 확장성을 지원합니다. 수많은 리소스에서 동시에 데이터를 수집하고 처리할 수 있으며, 수집된 데이터의 양과 복잡성에 따라 확장이 가능합니다.
CNCF 오픈 소스 프로젝트
- Opentelemetry는 Cloud Native Computing Foundation (CNCF)의 오픈 소스 프로젝트로서, 개발자들과 커뮤니티의 협력을 통해 지속적으로 발전하고 있습니다. 이는 안정성과 지속적인 개선이 보장되며, 다양한 기여자와 사용자들이 함께 Opentelemetry를 발전시키고 활용할 수 있음을 의미합니다.
AWS Distro for OpenTelemetry (ADOT)
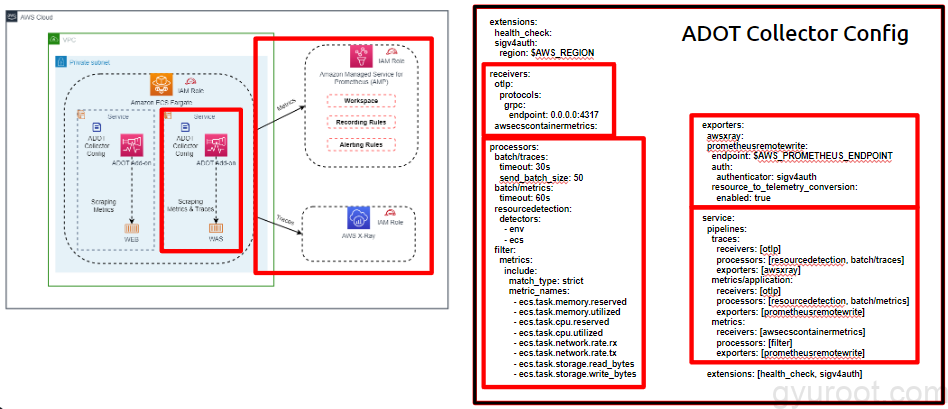
extensions
- health_check
- ADOT Collector의 상태 확인을 수행하는 확장 기능입니다.
- sigv4auth
- AWS 리전 정보를 사용하여 AWS 서비스와 통신하는 인증을 수행하는 확장 기능입니다.
receivers
- otlp
- OpenTelemetry Protocol(OTLP)을 통해 데이터를 수신하는 리시버입니다. gRPC 프로토콜을 사용하며, 0.0.0.0:4317 주소에서 수신합니다.
- awsecscontainermetrics
- AWS ECS 컨테이너 메트릭을 수신하는 리시버입니다.
processors
- batch/traces
- 추적 데이터를 일괄 처리하는 프로세서입니다. 30초의 제한 시간과 50개의 배치 크기로 데이터를 처리합니다.
- batch/metrics
- 메트릭 데이터를 일괄 처리하는 프로세서입니다. 60초의 제한 시간과 50개의 배치 크기로 데이터를 처리합니다.
- resourcedetection
- 환경 변수 및 AWS ECS에서 리소스 정보를 탐지하는 프로세서입니다.
exporters
- awsxray
- 추적 데이터를 AWS X-Ray로 내보내는 익스포터입니다.
- prometheusremotewrite
- 메트릭 데이터를 지정된 $AWS_PROMETHEUS_ENDPOINT 주소로 전송하는 Prometheus Remote Write 형식의 익스포터입니다. AWS 인증 정보를 사용하여 인증을 수행하며, 리소스를 텔레메트리로 변환하는 기능이 활성화되어 있습니다.
service
- traces 파이프라인
- otlp 리시버로부터 추적 데이터를 수신하고, resourcedetection 및 batch/traces 프로세서를 거쳐 awsxray 익스포터로 전송합니다.
- metrics/application 파이프라인
- otlp 리시버로부터 메트릭 데이터를 수신하고, resourcedetection 및 batch/metrics 프로세서를 거쳐 prometheusremotewrite 익스포터로 전송합니다.
- metrics 파이프라인
- awsecscontainermetrics 리시버로부터 메트릭 데이터를 수신하고, filter 프로세서를 거쳐 prometheusremotewrite 익스포터로 전송합니다.
Amazon Managed Grafana
✅ 프로젝트에 사용한 모니터링 도구는 Grafana입니다. Grafana는 데이터 시각화 및 모니터링을 위한 오픈 소스 도구입니다. 그래프와 대시보드를 생성하여 다양한 데이터 소스로부터 데이터를 시각화하고, 실시간으로 데이터를 모니터링하고 분석할 수 있습니다.
- opentelemetry를 이용
- Metric은 Prometheus
- Trace는 X-ray
- 데이터를 받은 다음 해당 데이터로 시각화하기 위해 Grafana 에서 해당 데이터를 Query
- Dashboard로 구현
💡 모니터링 골든 시그널 - Latency 요청을 완료하는데 걸리는 시간을 측정합니다. 평균 요청은 빠르게 완료될 수 있지만, 웹 애플리케이션의 가장 느린 요청에 중점을 두는 것이 중요합니다. - Traffic 페이지나 리소스 별로 트래픽을 살펴보고, 어떤 페이지가 가장 성공적이고 어떤 페이지가 개선이 필요한지 파악합니다. - Errors 실패한 요청 수 입니다. 내부 서비스 오류가 있음을 의미하는 500상태 코드를 반환하는 모든 HTTP 요청을 추적합니다. - Saturation 총 부하를 시각화 하며 보통 백분율로 표현합니다. 성능이 저하될 가능성을 낮추기 위한 모니터링입니다.
System Dashboard
- 서비스 가동률
- 현재 서비스 상태를 백분율로 표현하여 즉각적으로 인지할 수 있습니다.
- ECS Service Task 개수
- 취약점 중요도 별 count
- AWS 예상 비용 확인
- uptime
- Container가 혹시나 중간에 shutdown이 일어나지 않았는지 확인합니다.
- Request
- 총 요청수를 count하여 서비스 수요를 파악합니다.
- HTTP 5XX
- 서비스 오류율을 확인합니다.
- CPU,Memory
- 포화도를 확인 할 수 있습니다.
- Network Rx,Tx
- Traffic양을 확인합니다.

Security Dashboard
- 인프라 전반의 취약점을 파악할 수 있습니다.

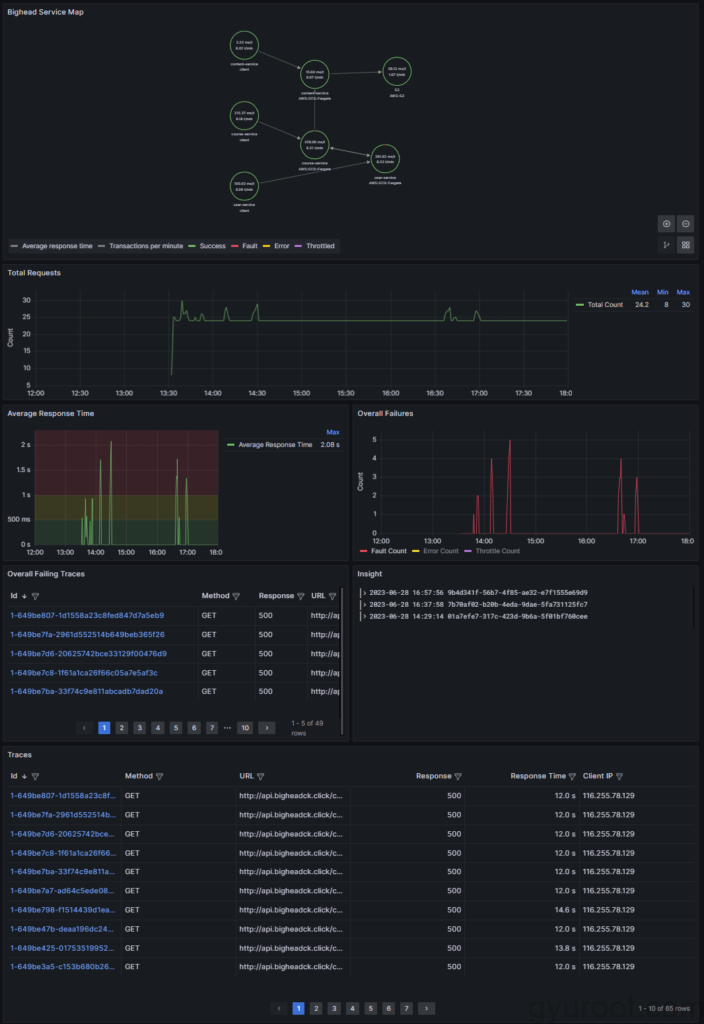
X-ray Dashboard
- Trace 경로
- 애플리케이션의 추적 경로를 시각적으로 표현합니다.
- 추적 경로를 따라가면서 각 단계의 실행 시간, 호출된 서비스 및 구성 요소 간의 상호 작용을 확인할 수 있습니다.
- 응답 시간 분석
- 각 추적에서의 응답시간을 시계열 그래프로 표시합니다.
- 애플리케이션의 성능을 모니터링하고 지연이 발생하는 지점을 식별할 수 있습니다.
- 오류율
- 추적에서 발생한 오류 정보를 시각화합니다.
- 애플리케이션의 문제를 신속하게 파악하고 디버깅합니다.
Trouble Shooting Log
Terraform 배포시 ECR 에서 image를 Pull하지 못함
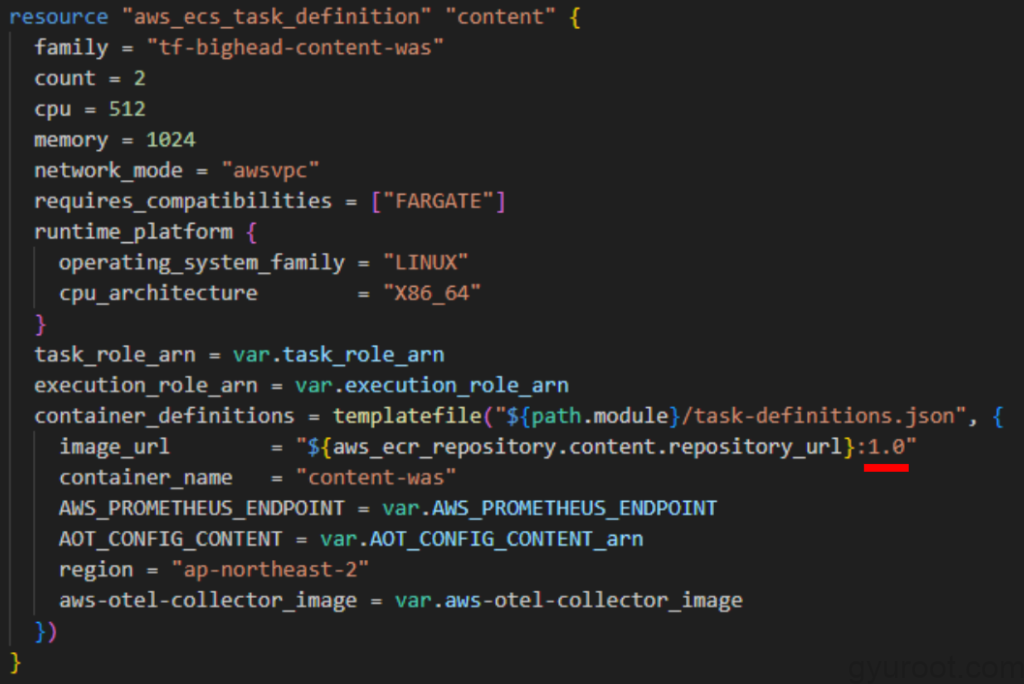
원인
- Task Definitions 필드에서 ECR image주소를 정의할 때 image이름까지 입력을 하지 않았습니다.
결과
- ECR Pull Error Event 발생
해결방안
- 왼쪽 이미지처럼 이름까지 입력
Grafana System Dashboard / Container 리소스 시각화
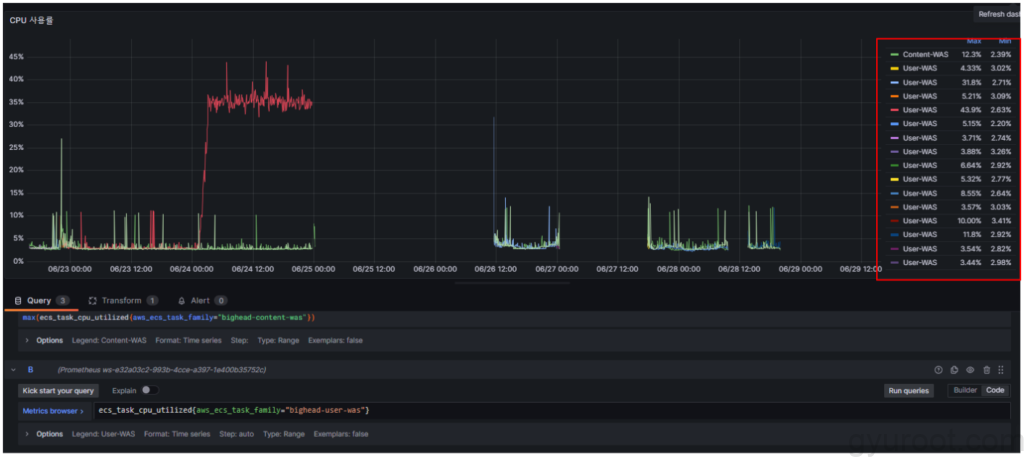
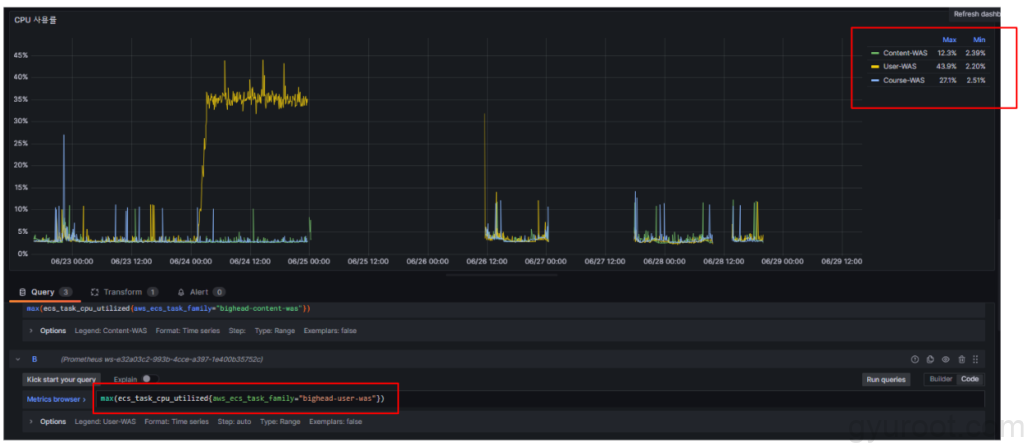
원인
- ECS에서 새개정으로 업데이트 할 때마다 수집된 메트릭이 전부 시각화 되면서 평균을 계산할 수 없거나 현재 실행중인 컨테이너로 특정 지을수가 없음
해결 방안
- max(ecs_task_cpu_utilized{aws_ecs_task_family=”[name]”}) ← 수정
- ECS 서비스에서 실행된 Container중에서 최대 사용률로 Query
취약점 점검 Report 문제(Lambda)


원인
- CloudWatch에서 넘어오는 데이터가 인코딩이 되어서 넘어오고 있었으며, Lambda 함수가 작동을 해도 이미 Security Hub의 로그를 보고 데이터 추출을 하는 코드로 되어있어서 추출할 데이터 값이 없었습니다.
해결 방안
- Decoding
Multi Account 환경에서 ADOT <> AMP 연동 문제

현상 로그
Exporting failed. The error is not retryable. Dropping data.{ “kind”: “exporter”, “data_type”: “metrics”, “name”: “prometheusremotewrite”, “error“: “Permanent error: Permanent error: remote write returned HTTP status 404 Not Found; err = %!w(<nil>): {\”Message\”:\”Workspace not found\”}”, “dropped_items”: 720 }
해결방안
- Observability Account에서 Develop Account의 ECS Task Role에 대한 신뢰 정책을 생성하고, AMP에 접근할 수 있는 Role을 생성
- Develop Account의 ECS Task Role에 2에서 생성한 Role에 대한 AssumeRole 권한 부여
- ADOT Collector Exporter에 sigv4auth extension 적용
자동 태그 추가시 S3 버킷에 태그 추가가 안되는 문제

원인
- 태그 추가 시 전달하는 JSON 파일의 형식이 맞지 않아서 생긴 문제
결과
- Tagging={‘TagSet’: [{“Key”: “bighead:Env”, “Value”: “PROD”}]}
- set_s3_attached_tags(s3_bucket_name, Tagging)
해결 방안
- JSON 형태 변경 후 S3 태그 추가 함수 호출
일일 보고서 스냅샷 생성할 때 API 전달 안되는 문제

원인
- 태그 추가 시 전달하는 JSON 파일의 형식이 맞지 않아서 생긴 문제
결과
- body 데이터를 json.dumps 함수를 이용하여 데이터 형태 변경 후 request 실행
해결방안
- http.request(‘POST’, URL, body=json.dumps(data3), headers=headerData, retries = False)
프로젝트 완료
프로젝트 결과 및 기대 효과
- Budget 서비스를 이용한 비용 관리
- AWS 예상치 못한 리소스 사용으로 불필요한 비용 지출 방지
- 지속적으로 늘어나는 자산 리소스 관리 복잡도 완화
- CloudTrail + Lambda + SSM Parameter Store 를 이용한 Tagging 자동화
- Tag 별로 리소스 그룹화
- 인프라 단일진입점 ALB에 AWS WAF 연결로 보안강화
- 전체 리소스중에 보안사고가 우려되는 관리형 규칙으로 선별하여 적용
- ALB 적용으로 가용성 확보
- ECS 배포 유형중 Fargate로 배포하여 확장성 고려
- 취약점 제거 및 위협 관리
- AWS Inspector 사용으로 실시간 CVE 취약점 업데이트 하여 취약점 조기 발견
- AWS Config 사용으로 실시간 CCE 취약점 조기발견
- AWS Security Hub 사용으로 보안취약점 중앙집중관리
- System Manager로 단순 해결 방법은 자동화 해결
- Lambda 를 통한 취약점 알림 설정
- Application, Infra, Security 모니터링
- 벤더 종속성 영향을 받지 않고 여러 언어에서 호환되는 Opentelemetry 사용으로 Metric, Trace, Logs 전
- 시스템 상태를 파악하기 위해 강력한 지표 데이터 수집 및 분석 기능을 제공하는 Prometheus 사용
- AWS-X-ray 사용으로 지속적인 애플리케이션의 성능 향상과 확장성 향상
- Amazon Managed Grafana 사용으로 데이터를 직관적이고 인터랙티브한 형태로 시각화하여 실시간으로 모니터링하고 분석할 수 있습니다. 이를 통해 데이터 기반의 의사결정을 지원하고, 문제를 신속하게 파악하여 대응
- CI/CD 파이프라인으로 자동 배포
- Github Action을 사용함으로써 개발자들은 자동화된 워크플로우를 구축하여 개발 및 배포 과정을 향상
프로젝트 후기
아키텍처 구성 중 가장 어려웠던 점
- Grafana Dashboard에서 query문 작성 및 원하는 시각화 만들기
- AWS Distro for OpenTelemetry [aws-otel-collector 배포 -> 수집 -> 전달] 동작 원리 이해 및 구현 과정
- Infra 최종 완성 후 Terraform 으로 IaC 과정
- Github Action을 이용한 CI/CD 과정 구현 중 ECS Task Definition 정의
- 리소스별 권한 및 역할 적용
- AWS WAF 관리형 규칙 선별, 우선순위 적용
새롭게 알게 된 지식
- AWS Security Hub, AWS Inspector, AWS Config
- AWS WAF
- AWS CloudTrail
- AWS X-ray
- OpenTelemetry
- Prometheus
- Grafana
- 자산관리시스템
- EAM : 전사자산관리시스템
- ITAM : IT자산관리시스템
지금까지 팀원과 부트캠프를 진행하면서 마지막 프로젝트여서 그런지 고생을 많이 했고 그만큼 많이 이뤄내고 성장하게된 프로젝트라고 생각합니다.
- 열심히 하는것도 좋지만 체력관리를 하면서 진행해야 한다.
- 프로젝트 진행하면서 꾸준히 저녁에 운동도 병행을 했었습니다. 그런데 어느 날 기분이 좋은 나머지 운동을 너무 격하게 하여 그 다음날 몸살 기운이 생겨서 프로젝트 진행하는데 방해가 될뻔했었습니다. 다행히 금요일 오후에 몸살 기운이 생겨서 주말에 충분히 휴식을 가질 수 있어서 프로젝트에 차질은 없었습니다.
- 아무리 급해도 충분히 이해하고 답변 및 진행한다.
- 팀원과의 협업 진행하면서 제일 중요한게 커뮤니케이션이라고 생각합니다. 대화 도중에 제가 충분히 이해하지 못했는데도 정해진 기한과 진행을 빠르게 하기 위해서 얼추 이해하고 다음으로 넘어간게 오히려 다시 확인해야 하는 역효과가 일어났으며 시간이 걸리더라도 충분히 이해하고 다음 단계로 넘어가는 습관을 들이게 되었습니다.
- 처음 다루는 서비스라도 충분히 해낼 수 있다.
- 언제 어디서나 처음은 긴장하게 되고 두렵습니다. 하지만 이번 프로젝트로 교육과정에서 다루지 않고 처음 다루는 서비스라도 해낼 수 있다는 것을 알게 되었고 앞으로도 해낼 수 있는 자신감을 얻게 되었습니다.
- 부정적인 마인드는 떨쳐내야 한다.
- 진행하면서 못할 수도 있고 교육을 받았음에도 불구하고 기억에 남지 않았던게 가끔 있었는데 이런일이 있을때마다 자신을 탓하고 걱정만 쌓이게 되었으며 이런 감정이 팀원에게도 전달 되는 듯한 느낌이 들었습니다. 그래서 실수를 하더라도 긍정적으로 바로잡게 되는 성향으로 거듭나게 되었습니다.
끝으로 프로젝트를 같이 진행한 팀원들에게 감사드리며 마치겠습니다.