
# 학습 목표
- EC2 서버를 ASG를 통해 구성합니다. 구성은 다음을 따릅니다.
- CloudWatch 알람을 통해 ASG의 스케일 인/아웃을 진행합니다.
- 스케일 인/아웃이 진행될 때 디스코드에 알림을 보냅니다.
- 메트릭을 바탕으로 장애 발생 예상 시점에 디스코드에 알림을 보냅니다.
# 해결 과제
시작 템플릿 구성
ASG를 위한 시작 템플릿 구성은 다음을 따릅니다.
- 그룹 정보
- 시작 템플릿은 다음 구성을 따릅니다.
CloudWatch와 조정 정책
- CloudWatch를 통한 Auto Scaling 그룹 지표 수집 활성화 필요
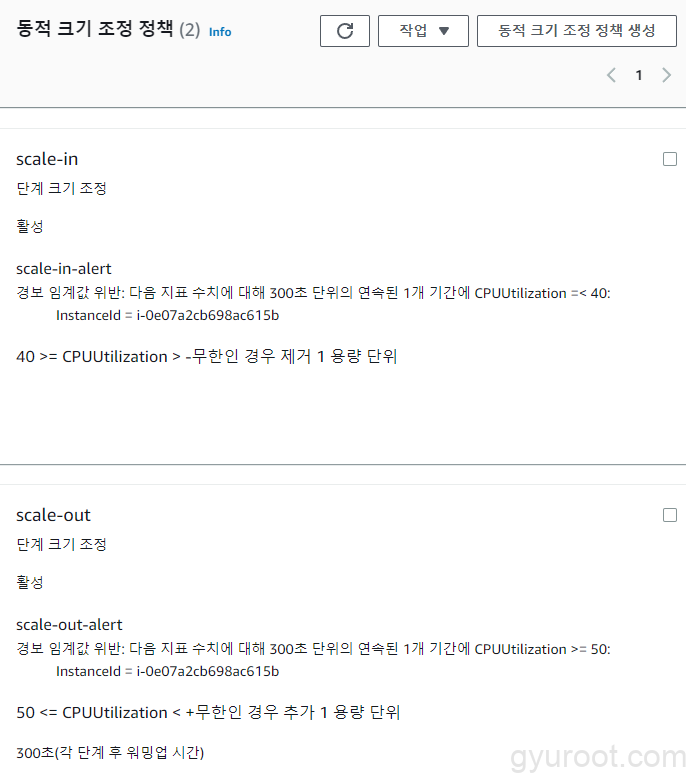
- Scale-in 조건: CPU 40% 이하
- Scale-out 조건: CPU 50% 이상
기타
- 로드 밸런서는 설정X
과제 이미지 예시

# 실습 자료
Lambda 함수 코드 : sns_to_discord.py
# 과제 항목별 진행 상황
1. 시작 템플릿 생성
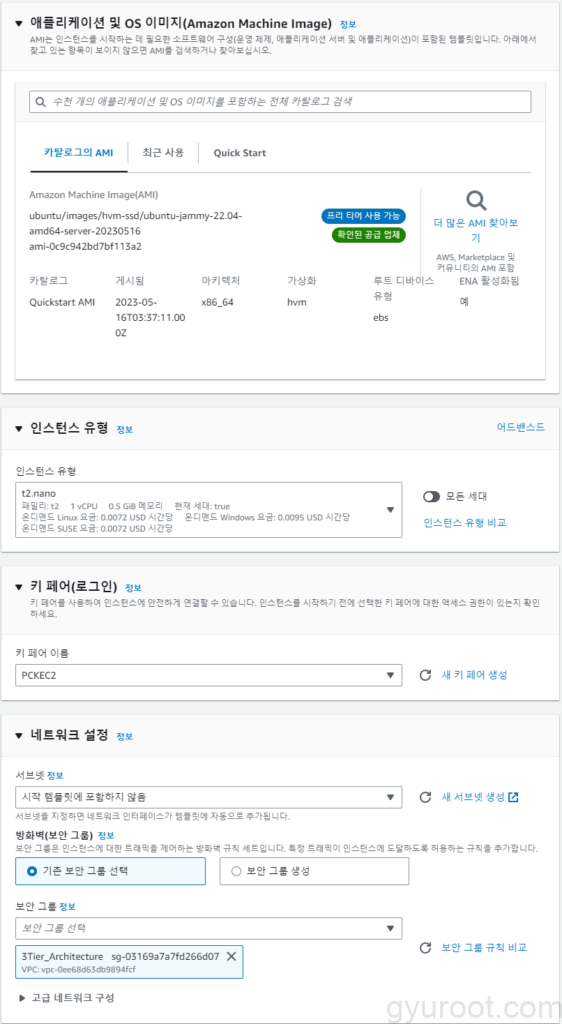
2. Auto Scaling 그룹 생성
- 1단계 – 시작 템플릿 또는 구성 선택

- 2단계 – 인스턴스 시작 옵션 선택 💡인스턴스 유형에 맞게 서브넷 지정

- 3단계 – 고급 옵션 구성(기본값)
- 4단계 – 선택 사항 – 그룹 크기에서 최대용량만 3으로 지정 후 나머지는 기본값
- 5단계 – 알림추가 (skip)
- 6단계 – 태그추가 (skip)
- 7단계 – 검토 후 완료
3. Auto Scaling 그룹 동적 크기 조정 정책 생성
EC2 → Auto Scaling → Auto Scaling 그룹 → 생성한 그룹 선택 후 자동 크기 조정 → 동적 크기 조정 정책 생성 클릭 후 아래와 같은 조건으로 생성
4. SNS Topic 생성
- 표준 유형으로 생성
5. Lambda Function 생성 및 코드 추가 후 SNS 구독


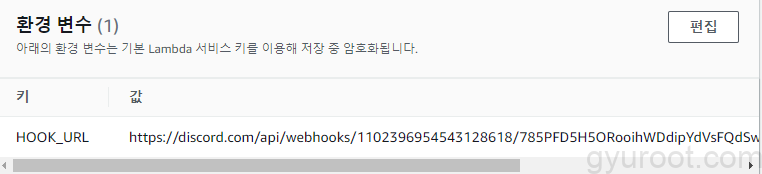
6. Cloud watch 경보 설정
- 경보 → 모든 경보 → 경보 생성 → 지표 선택

- 1단계 – 지표 및 조건 지정

- 2단계 – 작업 구성


- 3단계 – 이름 및 설명 추가 (이름 :
Scale-out-alert) - 4단계 – 미리 보기 및 생성
Scale-out-alert생성 후 동일한 과정으로 하되 CPU 임계값이 40%아래로 내려갔을때의 조건으로Scale-In-alert추가생성

7. Test
- EC2 SSH 접속 후
top명령으로 실시간으로 확인

top - 04:02:51 up 2:17, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 102 total, 1 running, 101 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.0 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 462.5 total, 28.1 free, 183.3 used, 251.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 252.8 avail Mem- 터미널 추가 실행 후 EC2 SSH 접속
stress -c 1명령을 통해서 아래와 같이 CPU 부하 진행

top - 04:06:36 up 2:21, 2 users, load average: 0.53, 0.14, 0.05
Tasks: 104 total, 2 running, 102 sleeping, 0 stopped, 0 zombie
%Cpu(s): 99.7 us, 0.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 462.5 total, 26.7 free, 184.7 used, 251.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 251.4 avail Mem- 🆗아래와 같이 나오면 성공!

- scale-out 일 때 인스턴스 추가 확인

- scale-in 일 때 인스턴스 제거 확인

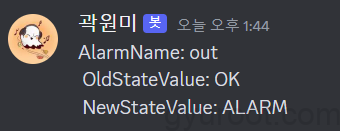
8. SNS를 통해서 받은 메세지
- AlarmName
- OldStateValue
- NewStateValue
💡Lambda Function에서 위와 같은 필드만 지정해서 디스코드로 전달했지만 아래 필드를 확인하여 추가적으로 메세지를 보낼 수 있다.
{
"Origin": "AutoScalingGroup",
"Destination": "EC2",
"Progress": 50,
"AccountId": "159088646233",
"Description": "Terminating EC2 instance: i-0e07a2cb698ac615b",
"RequestId": "6a608523-ea30-4a9b-8962-308a8c5277b6",
"EndTime": "2023-06-01T01:52:20.959Z",
"AutoScalingGroupARN": "arn:aws:autoscaling:ap-northeast-2:159088646233:autoScalingGroup:70325c29-4629-4d44-94ff-5a03197554d7:autoScalingGroupName/sprint-ASG",
"ActivityId": "6a608523-ea30-4a9b-8962-308a8c5277b6",
"StartTime": "2023-06-01T01:51:39.279Z",
"Service": "AWS Auto Scaling",
"Time": "2023-06-01T01:52:20.959Z",
"EC2InstanceId": "i-0e07a2cb698ac615b",
"StatusCode": "InProgress",
"StatusMessage": "",
"Details": {
"Subnet ID": "subnet-002f2984e4582edf9",
"Availability Zone": "ap-northeast-2a",
"InvokingAlarms": [
{
"AlarmArn": "arn:aws:cloudwatch:ap-northeast-2:159088646233:alarm:scale-in-alert",
"Trigger": {
"MetricName": "CPUUtilization",
"EvaluateLowSampleCountPercentile": "",
"ComparisonOperator": "LessThanOrEqualToThreshold",
"TreatMissingData": "",
"Statistic": "AVERAGE",
"StatisticType": "Statistic",
"Period": 300,
"EvaluationPeriods": 1,
"Unit": null,
"DatapointsToAlarm": 1,
"Namespace": "AWS/EC2",
"Threshold": 40
},
"AlarmName": "scale-in-alert", //실습에서 사용했던 필드
"AlarmDescription": "# gyuroot n### scale-in-alert",
"AWSAccountId": "159088646233",
"OldStateValue": "ALARM", //실습에서 사용했던 필드
"Region": "Asia Pacific (Seoul)",
"NewStateValue": "ALARM", //실습에서 사용했던 필드
"AlarmConfigurationUpdatedTimestamp": 1685583763117,
"StateChangeTime": 1685583930916
}
]
},
"AutoScalingGroupName": "sprint-ASG",
"Cause": "At 2023-06-01T01:51:30Z a monitor alarm scale-in-alert in state ALARM triggered policy scale-in changing the desired capacity from 2 to 1. At 2023-06-01T01:51:39Z an instance was taken out of service in response to a difference between desired and actual capacity, shrinking the capacity from 2 to 1. At 2023-06-01T01:51:39Z instance i-0e07a2cb698ac615b was selected for termination.",
"Event": "autoscaling:EC2_INSTANCE_TERMINATE"
}# TROUBLE SHOOTING LOG
💡 문제 내용
원인
해결 방안
#References
내용